「Pythonクローリング&スクレイピング」を写経してみる(1)第1章「クローリング・スクリピングとは何か」
Deep Learning用の元データ集めの参考になるかなと思って衝動買いした以下の本
加藤 耕太 (著)
Pythonクローリング&スクレイピング ―データ収集・解析のための実践開発ガイド
3,456円
サポートページ
http://gihyo.jp/book/2017/978-4-7741-8367-1/support
まずはお決まりの環境構築から
(環境)
Panasonic CF-RZ4
Windows8.1
(0)上記本のAppendixにのっている、「Vagrantによる開発環境の構築」を写経してみる
mkdir scraping-book cd scraping-book vagrant box add ubuntu/trusty64
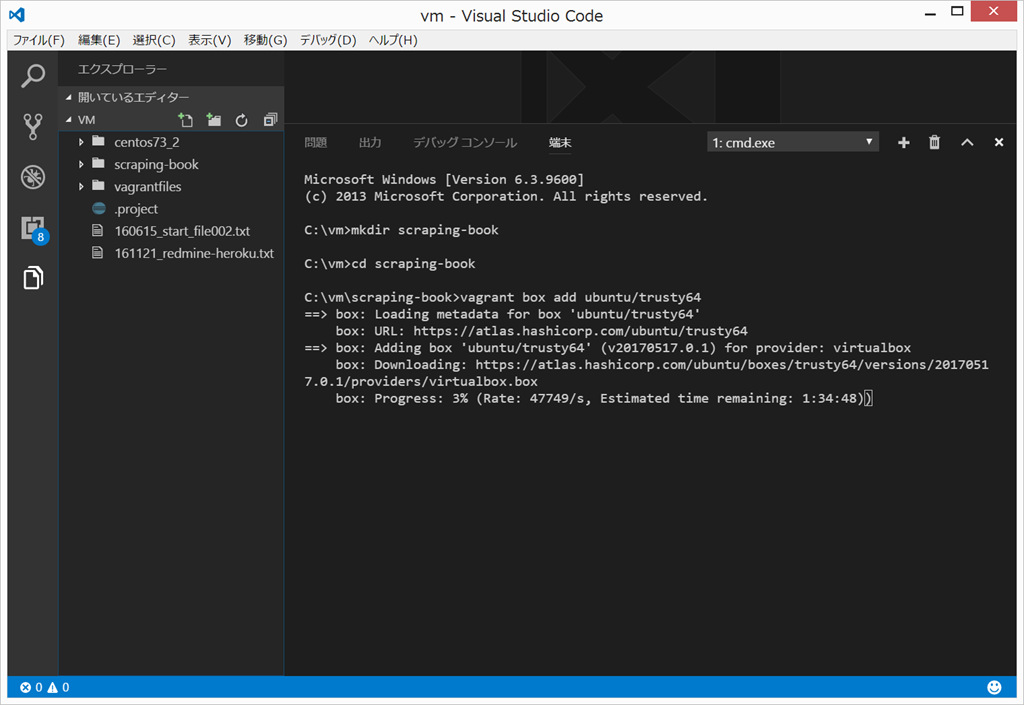{kind=link}
はい、vagrant boxのダウンロードに3時間くらいかかるらしいです。。。はい。。。無理かな。。。
{kind=link}
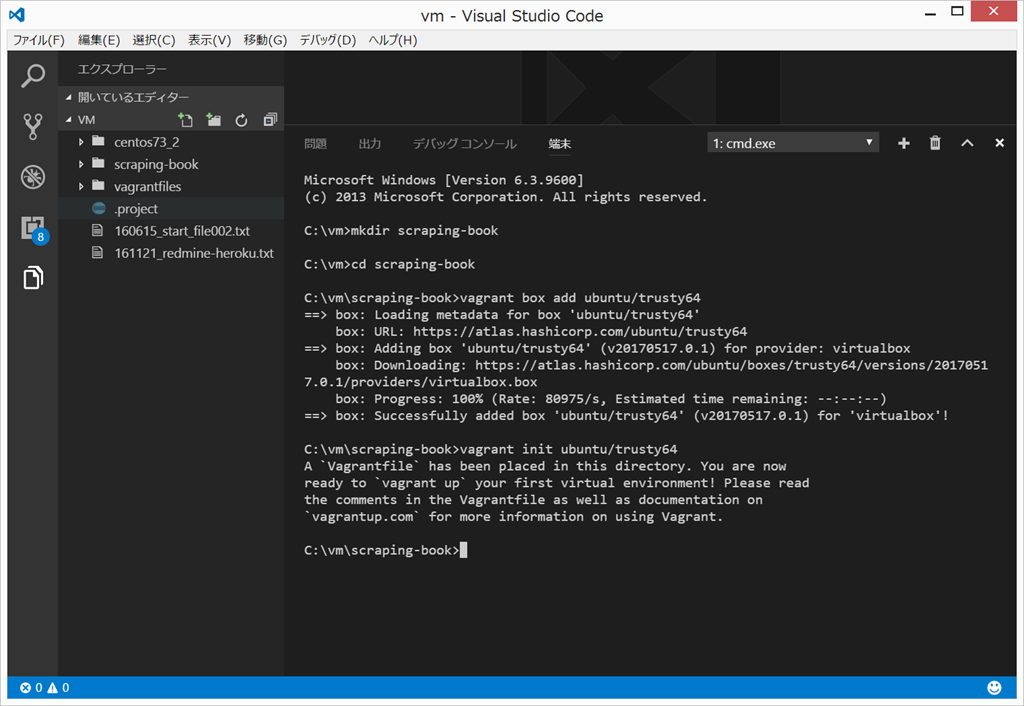
vagrant init ubuntu/trusty64
Vagrantfile の修正
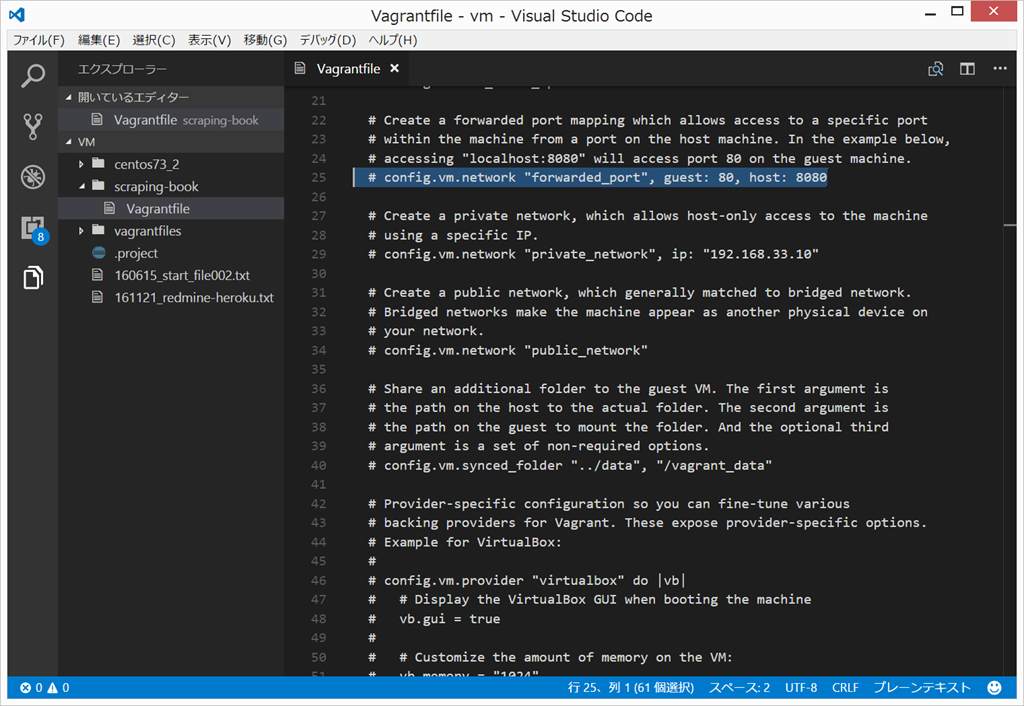{kind=link}
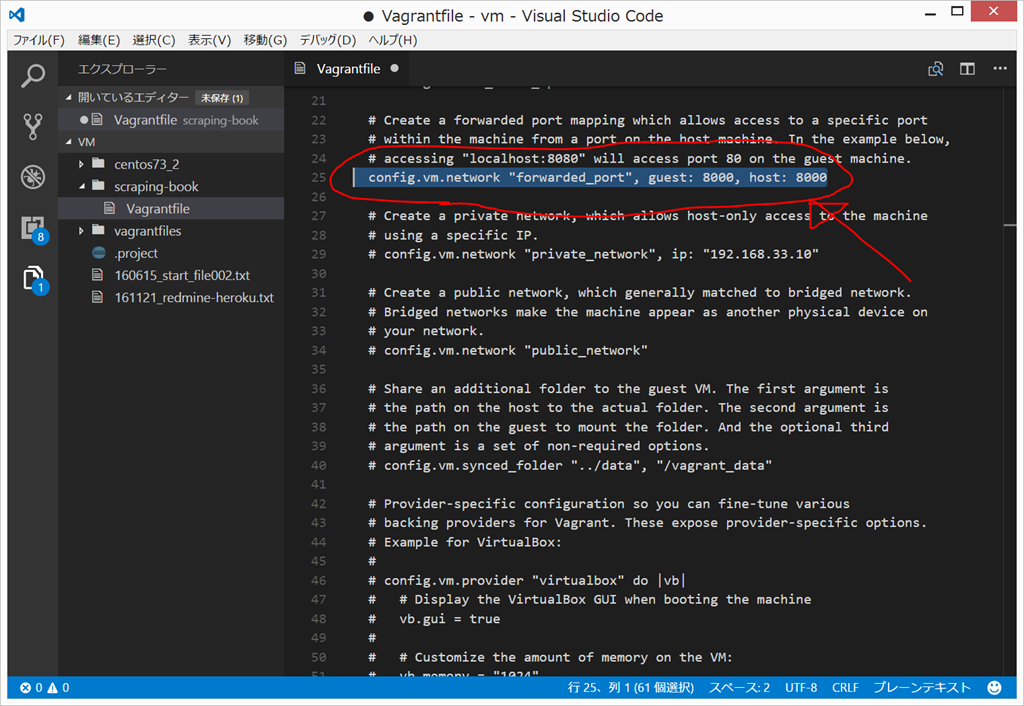{kind=link}
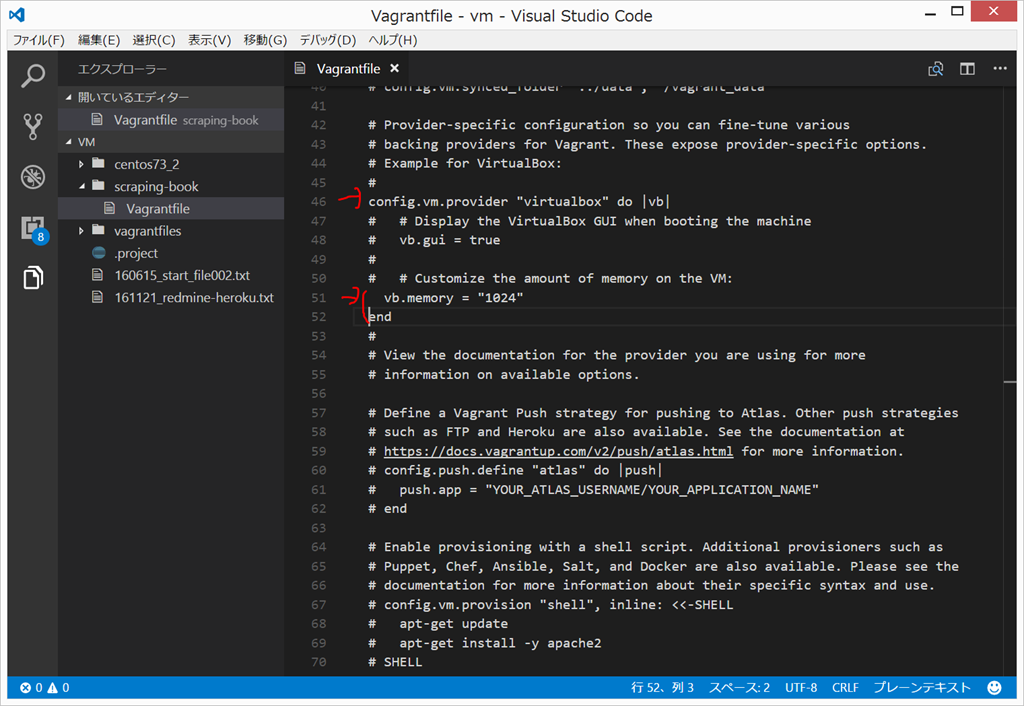{kind=link}
vagrant up
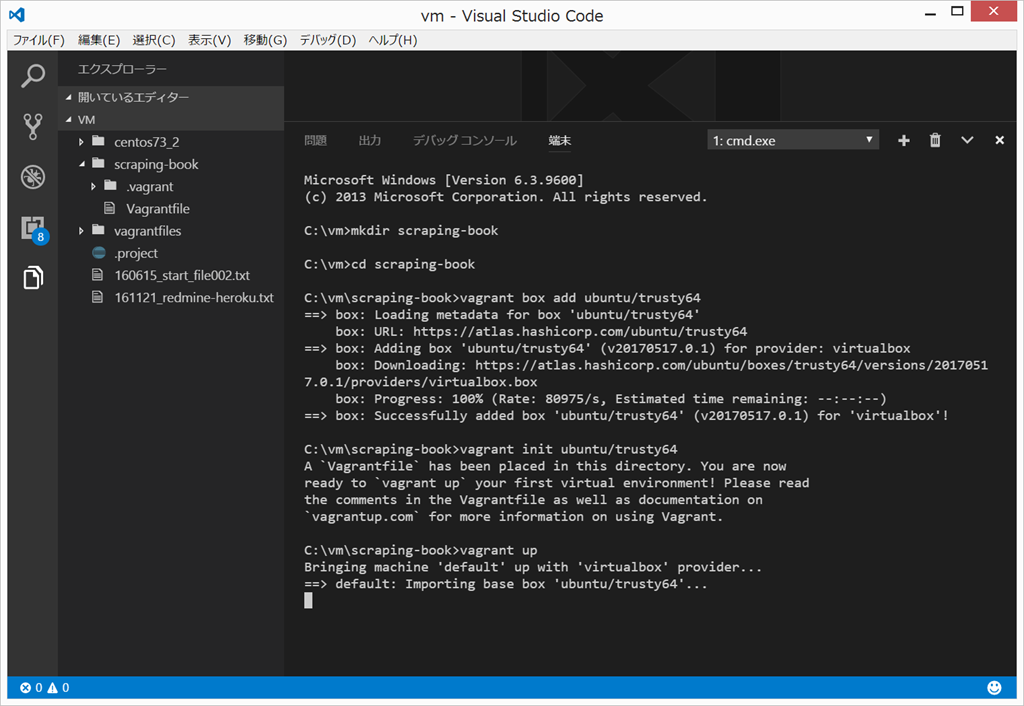{kind=link}
{kind=link}
なんかこれもまた10分以上かかっている気がする。
TeraTermでログイン
127.0.0.1
2222
vagrant
vagrant
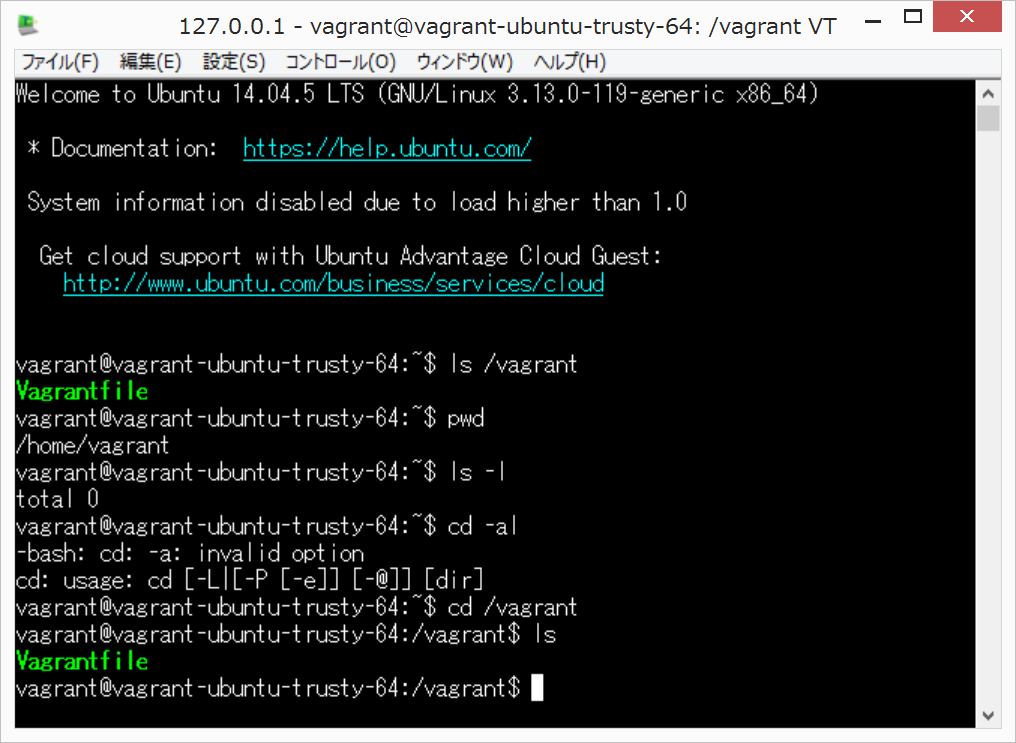{kind=link}
終了するときは、「exit」でTeraTermを修了し、ホストOSのコマンドプロンプトで、vagrant halt とすればよい。
再開するときは、ホストOSのコマンドプロンプトで、varant up してから、上記と同様にTeraTermでログインすればよい。
このあたりは、Ruby on Railsの環境構築でさんざんやったので、個人的には慣れている。
(1)Wget
sudo apt-get update
sudo apt-get install -y wget
{kind=link}
wget http://image.gihyo.co.jp/assets/templates/gihyojp2007/image/gihyojp_logo.png
{kind=link}
{kind=link}
{kind=link}
(2)実際のサイトのクローリング
上記本の筆者が作成してくださった練習用サイト
http://sample.scraping-book.com/dp
{kind=link}
wget -r --no-parent -w 1 -l 1 --restrict-file-names=nocontrol http://sample.scraping-book.com/dp/
なんか、3分くらいかかった。
{kind=link}
sudo apt-get install tree
tree sample.scraping-book.com/
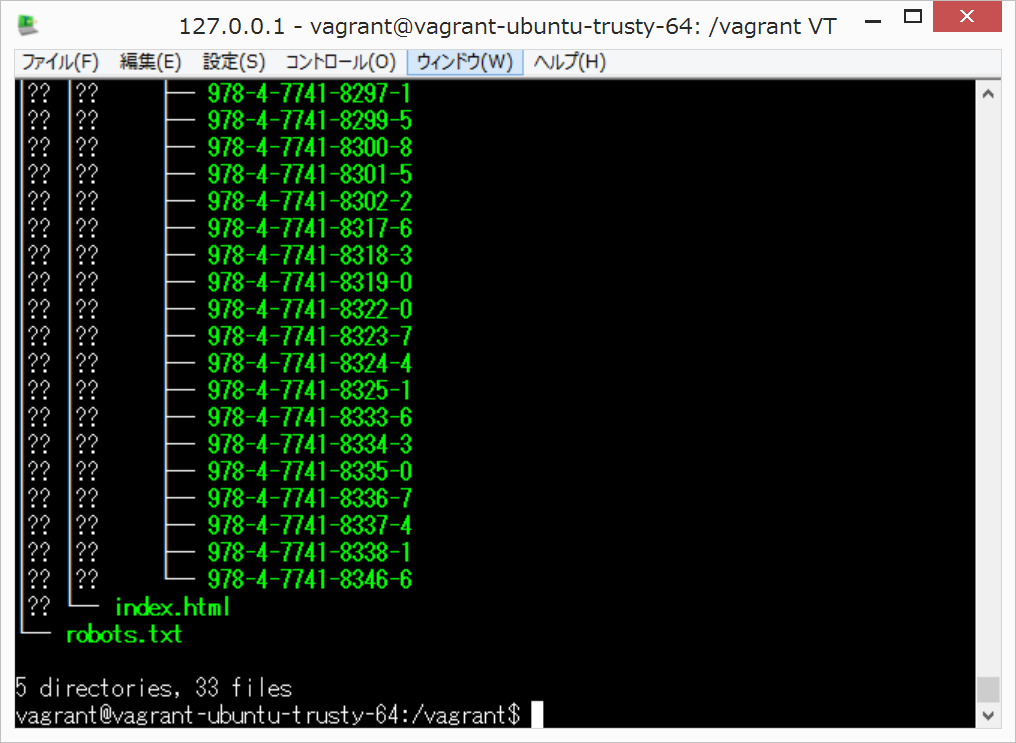{kind=link}
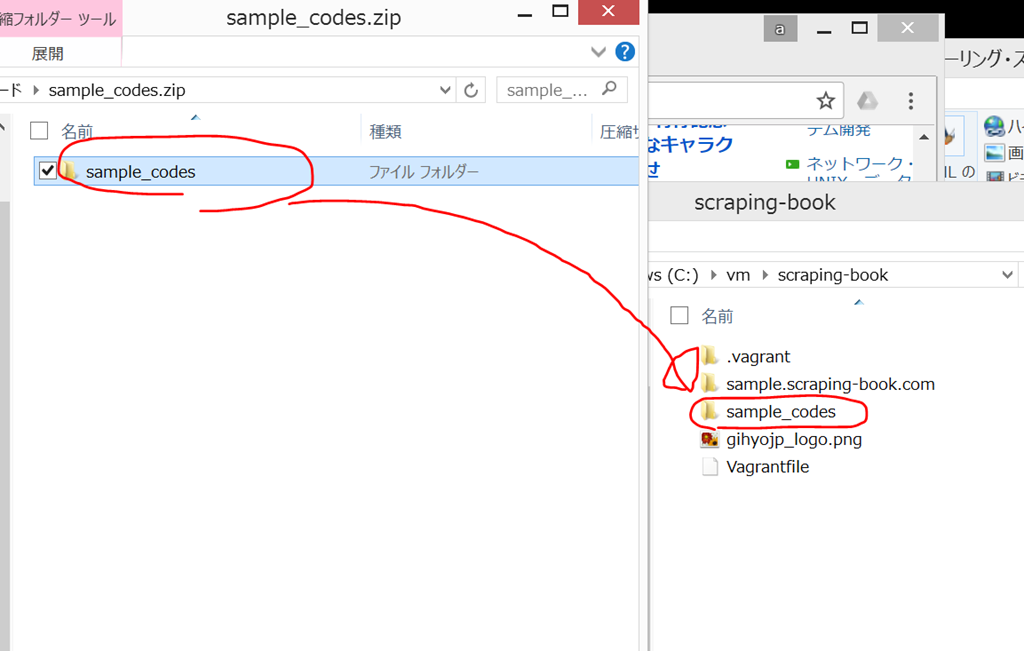
サポートページ
http://gihyo.jp/book/2017/978-4-7741-8367-1/support
から、sample_codes.zip をダウンロードして展開して、C:/vm/scraping-book/ フォルダに保存。
{kind=link}
{kind=link}
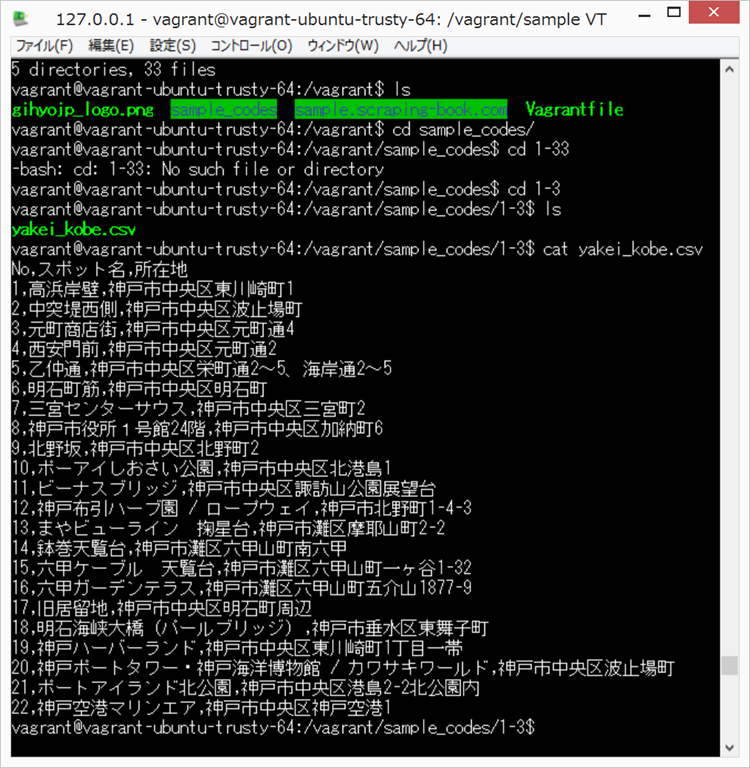
cd /vagrant/sample_codes
cd 1-3
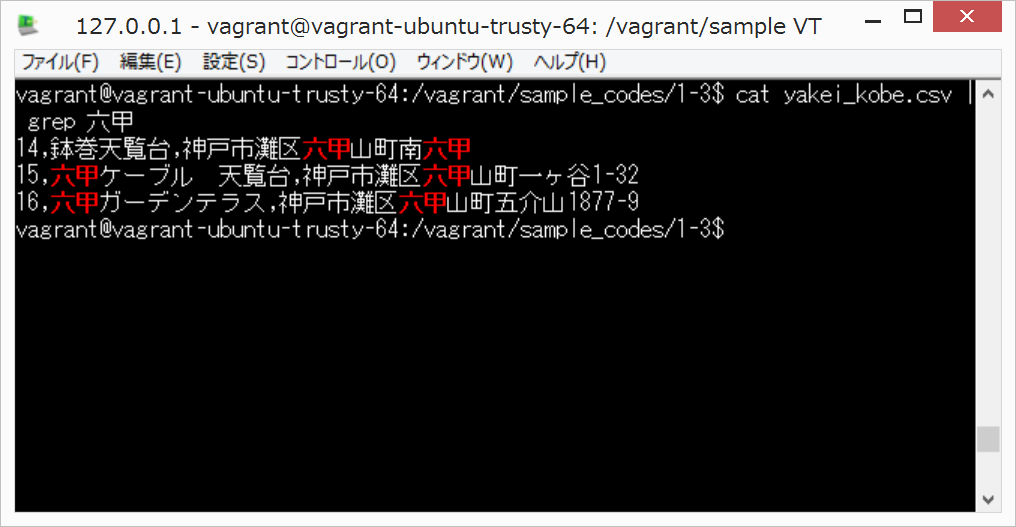
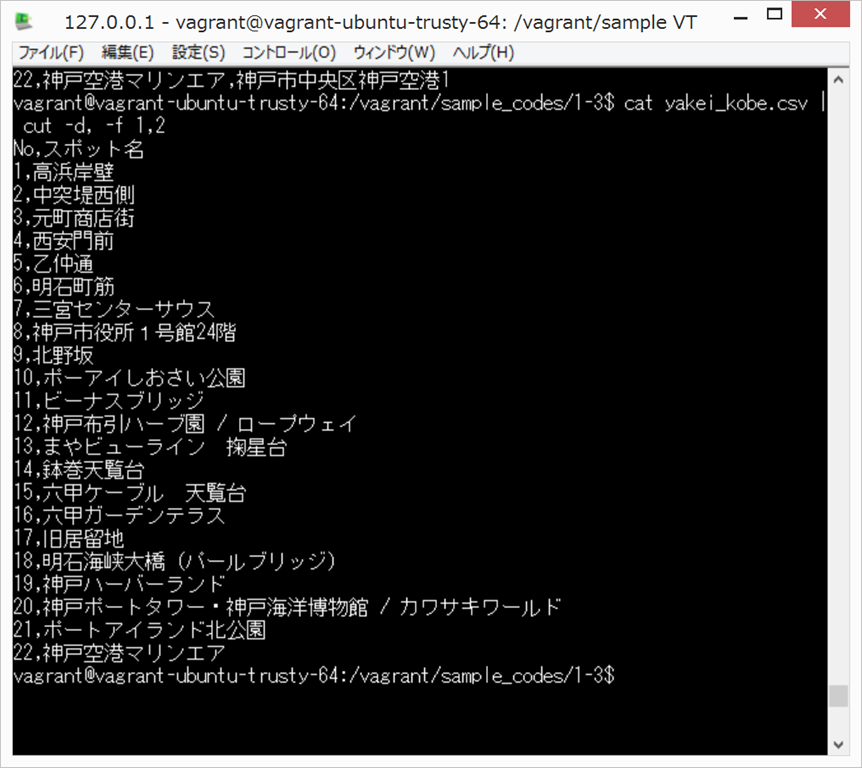
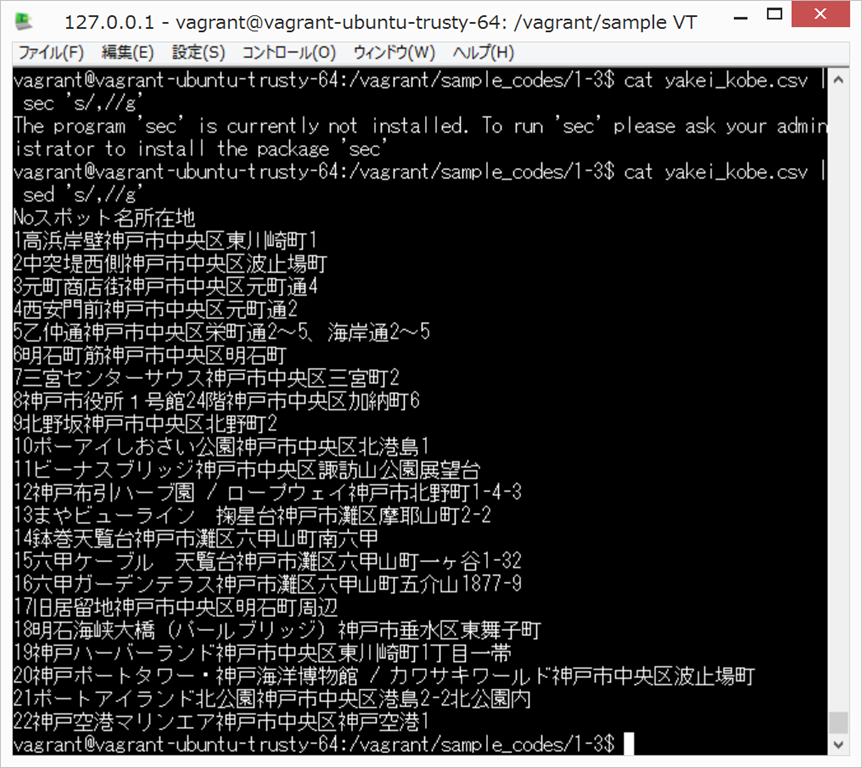
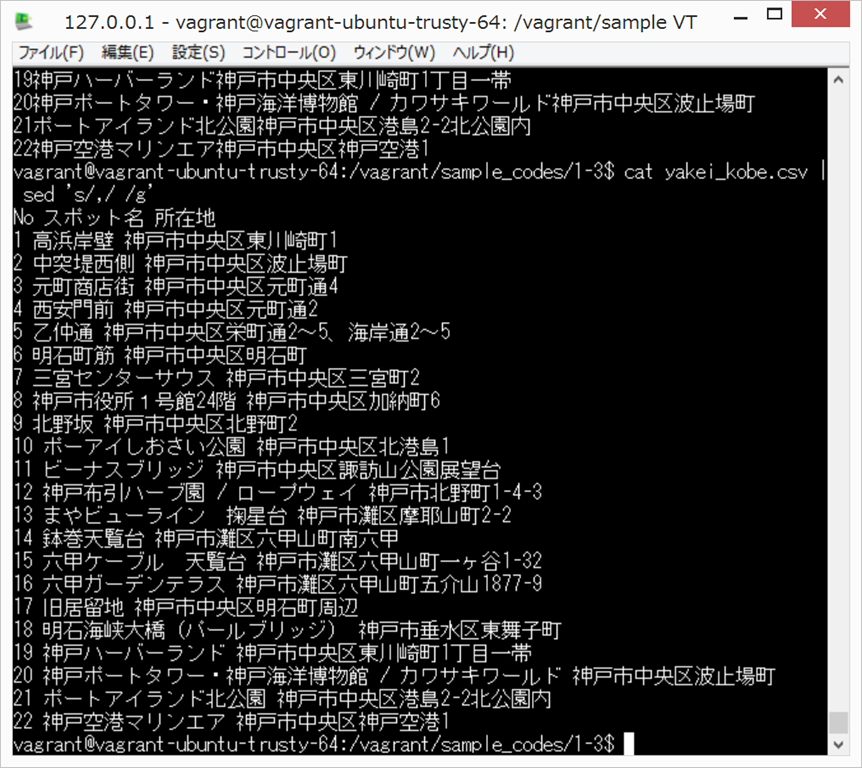
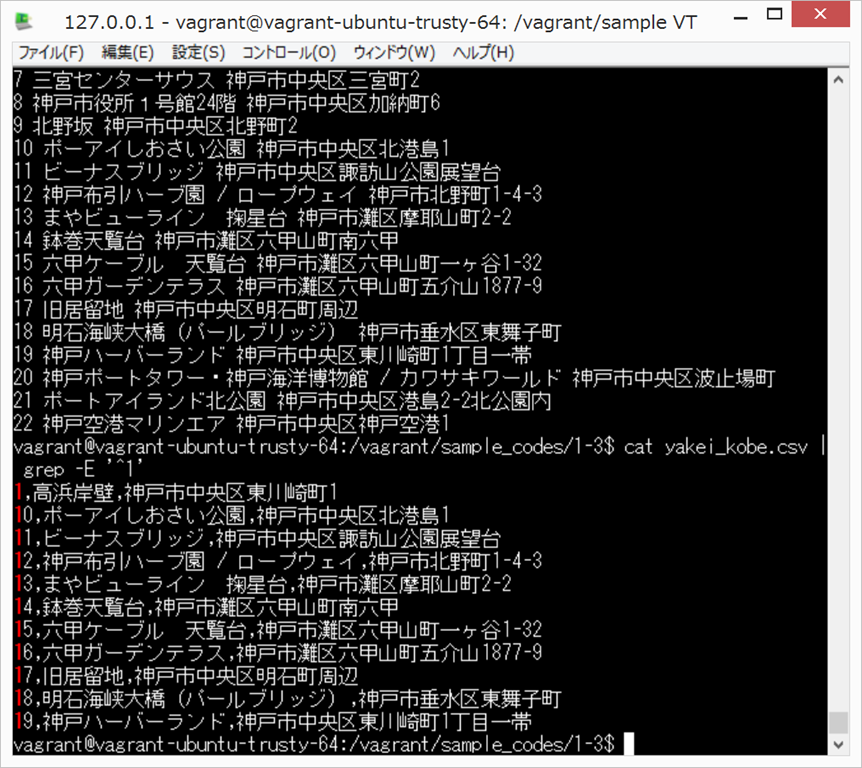
cat yakei_kobe.csv
{kind=link}
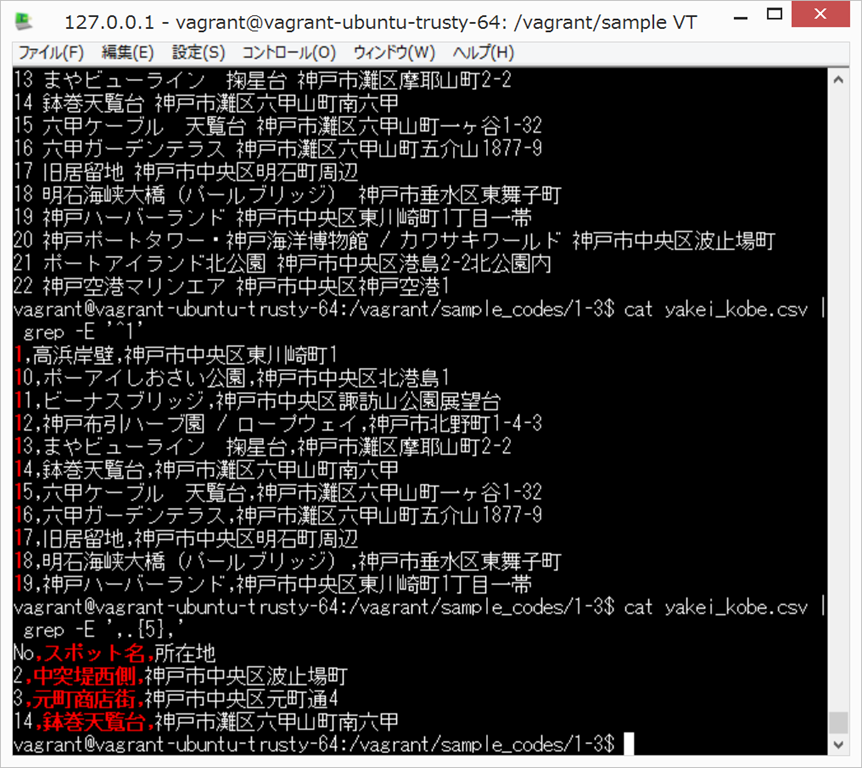
cat yakei_kobe.csv | grep 六甲
「|」(縦棒、パイプ)は、私のキーボードだと、Backspaceの左側にある。
{kind=link}
日本語が文字化けしないのが地味にうれしい。(Windowsだと必ず文字化けしていた気がする)
{kind=link}
{kind=link}
{kind=link}
正規表現(Regular Expression)、難しくて、すごくとっつきにくいです。
{kind=link}
{kind=link}
(3)gihyo.jp のスクレイピング
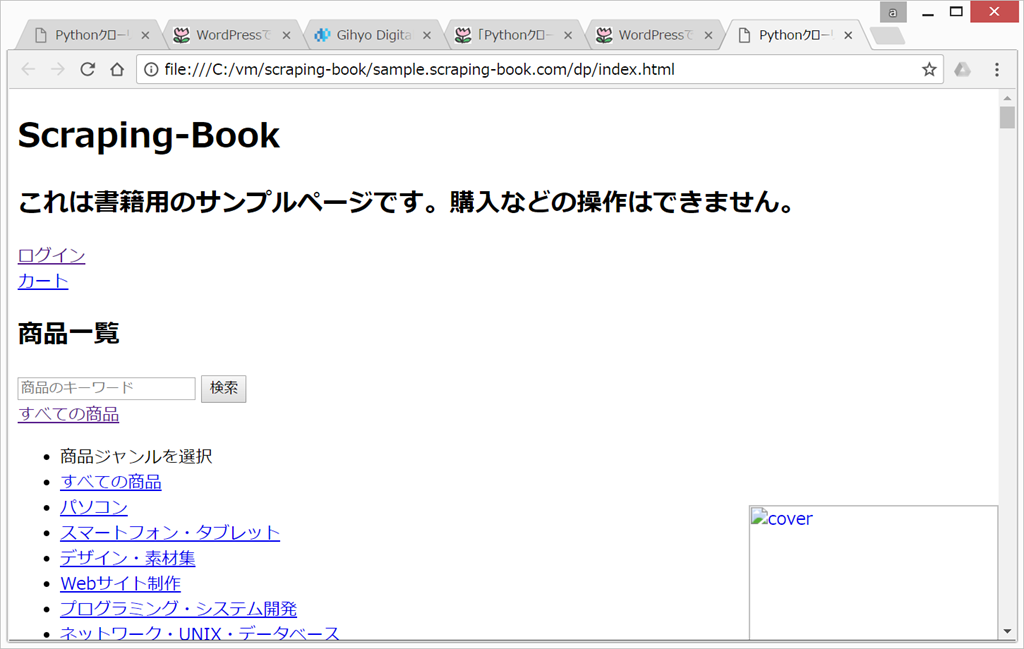
サンプルサイトのスクレイピングが以下のようになってしまったので、再度、ダウンロード
{kind=link}
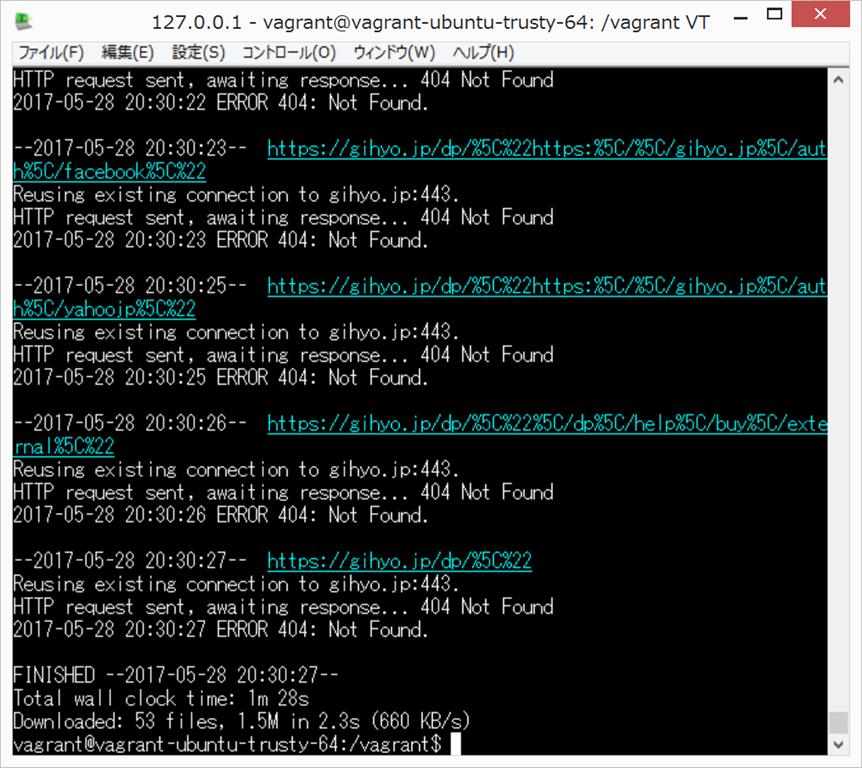
wget -r --no-parent -w 1 -l 1 --restrict-file-names=nocontrol http://gihyo.jp/dp/
{kind=link}
tree gihyo.jp/
{kind=link}
ダウンロードしたindex.htmlを開いてみると、あら、これでもダメだった。CSSが反映されていない。画像もダウンロードされていない。よくわからない。
{kind=link}
難しい。。。
{kind=link}
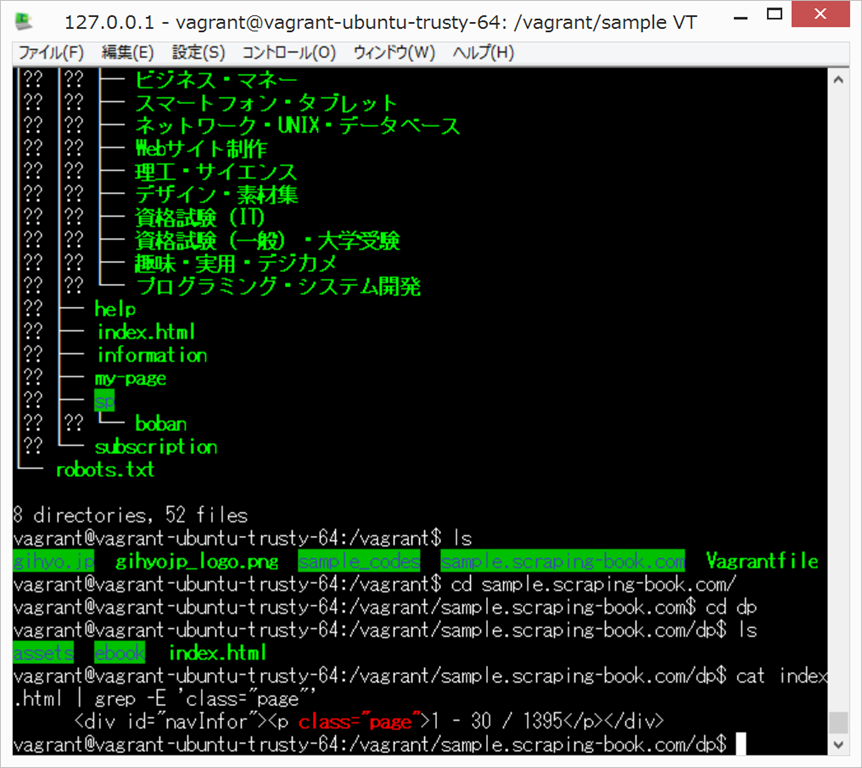
cd /vagrant/scraping-book/sample.scraping-book.com/dp/
cat index.html | grep -E 'class="page"'
{kind=link}
sudo apt-get update
sudo apt-get install -y wget
途中