GoogleColaboratory上で「PythonとKerasによるディープラーニング」を写経してみる(3)「多クラス分類の例:ニュース配信の分類」
「PythonとKerasによるディープラーニング」を、Google Colaboratory上で写経して、理解しようとしています。
前回は、第3章を最初の部分「二値分類の例:映画レビューの分類」を写経してみました。
http://twosquirrel.mints.ne.jp/?p=27159
今回は、その続きで、第3章の、「多クラス分類の例:ニュース配信の分類」を写経してみたいと思います。
(開発環境)
Windows 8.1 Pro (MacでもLinuxでも同じです。)
Chrome
Google Colaboratory (Googleアカウント必要、無料)
Keras をインストール済み(こちらを参照)
(1)Reutersデータセット
1986年にReutersによって配信された短いニュース記事と、それらのトピック(46種類)を集めたもの。
テキスト分類用の単純なデータセットとして有名。
Kerasの一部としてパッケージされている。
{kind=link}
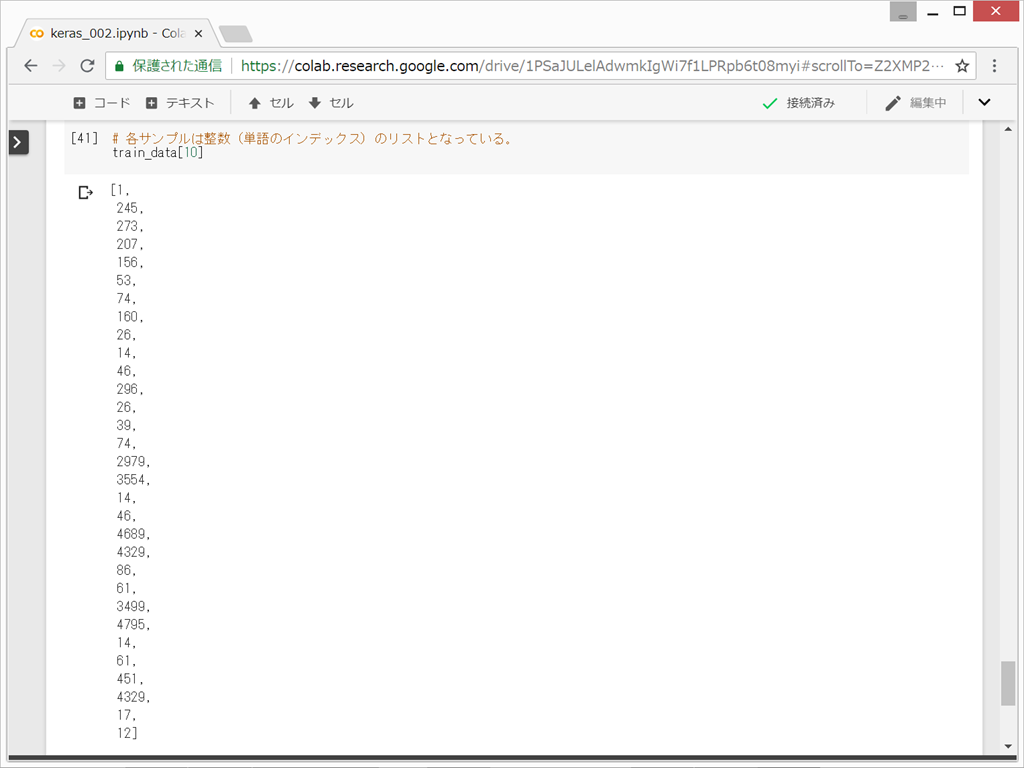
各サンプルは整数(単語のインデックス)のリストとなっている。
{kind=link}
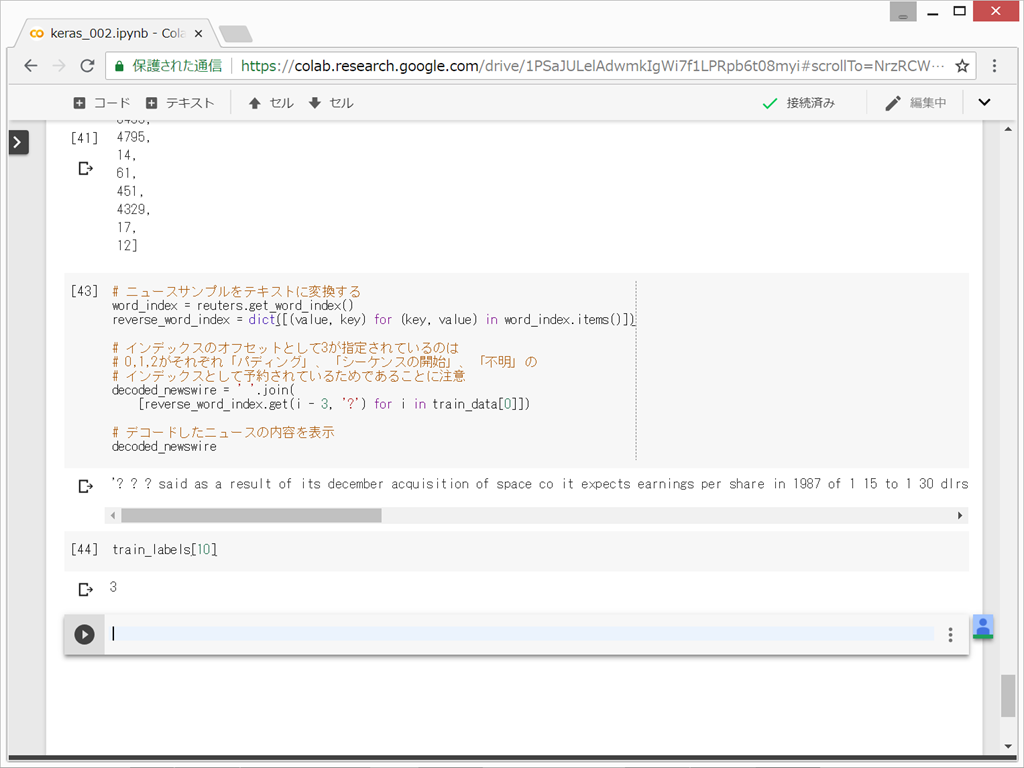
この整数のリストを、単語に戻してみる。
{kind=link}
なんか変な文章だが、とりあえず、次へ行く。
(2)データの準備
データのベクトル化は、二値分類のときと全く同じコード。
ラベルのベクトル化は、以下の2つの選択肢がある。
●ラベルのリストを整数のテンソルとしてキャスト(型変換)する方法
●one-hot encoding (= categorical encoding) ←こちらを用いる
# Kerasでは、ラベルのベクトル化を簡単に行うことができる
from keras.utils.np_utils import to_categorical
{kind=link}
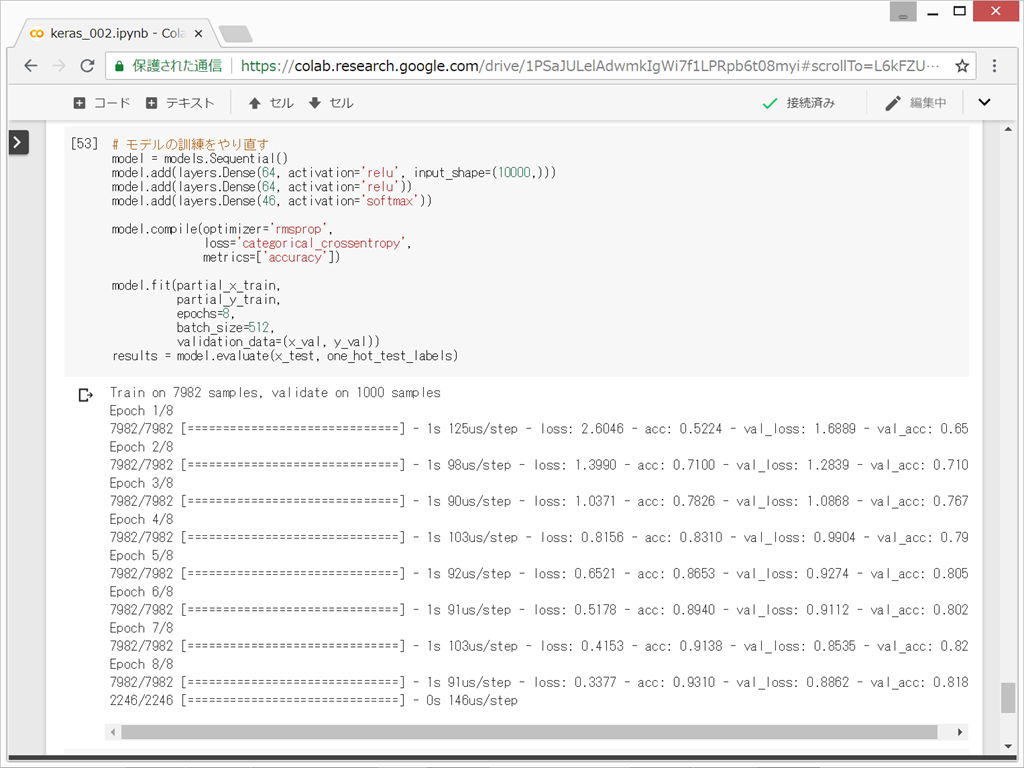
(3)ニューラルネットワークの構築
{kind=link}
{kind=link}
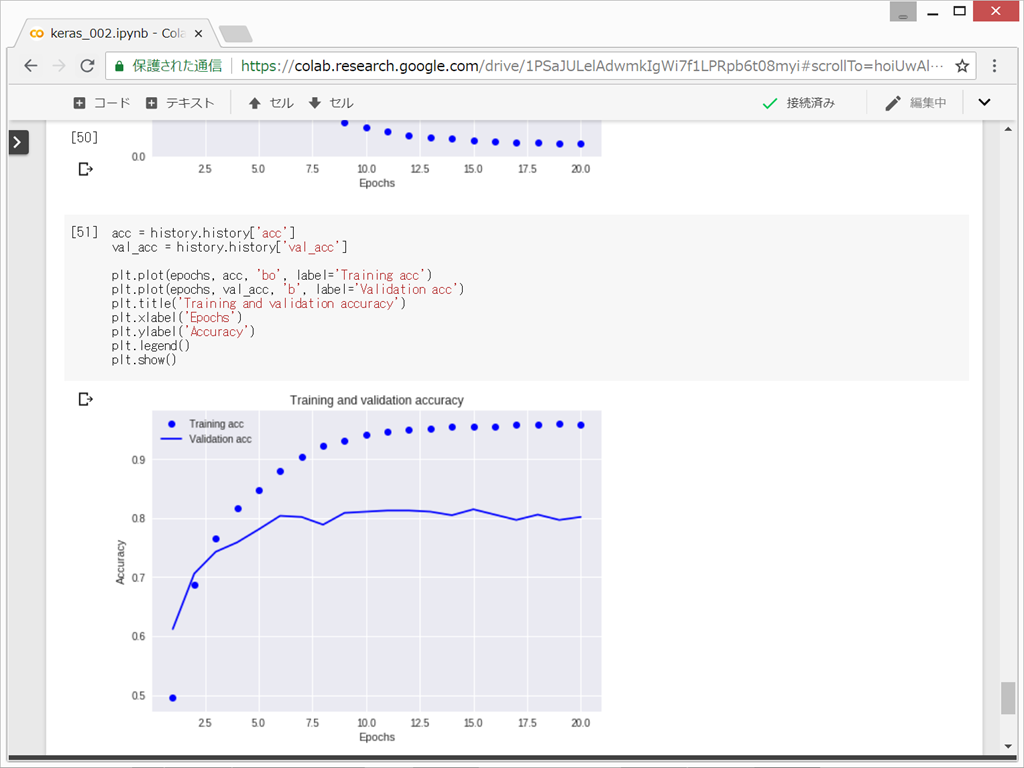
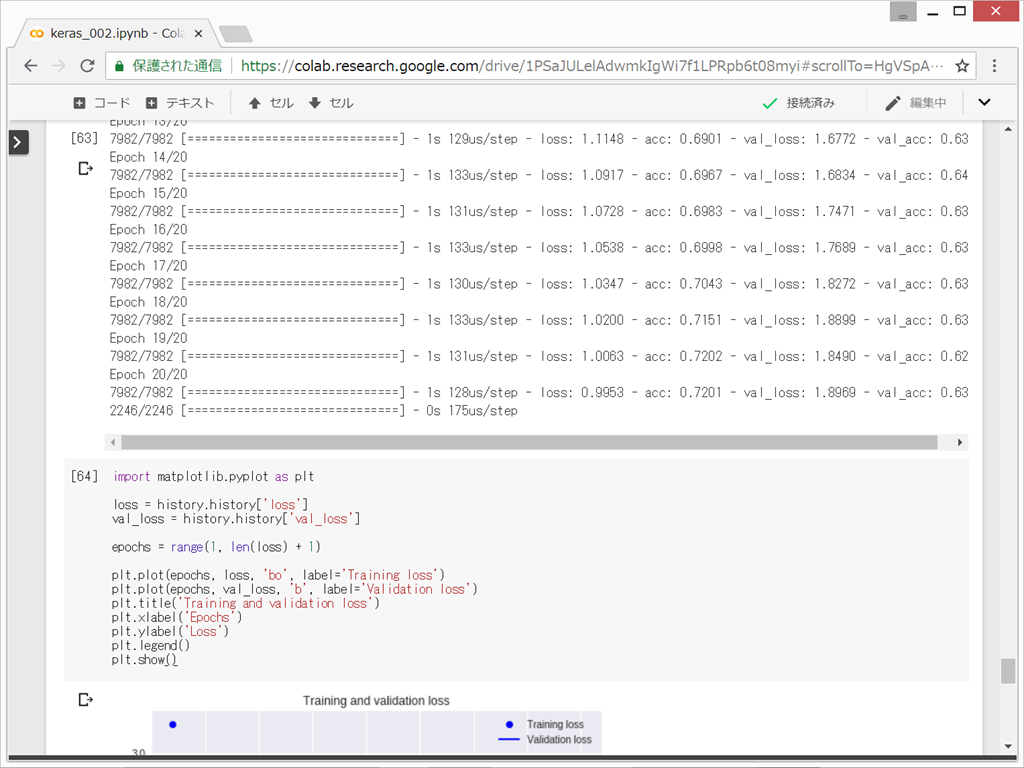
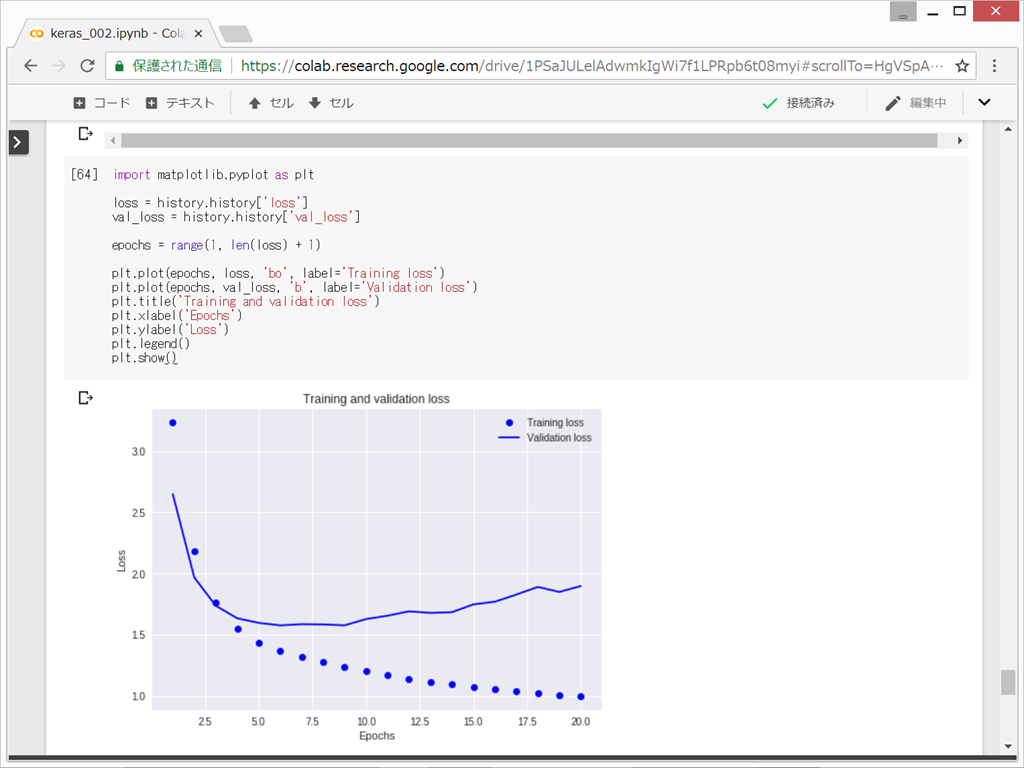
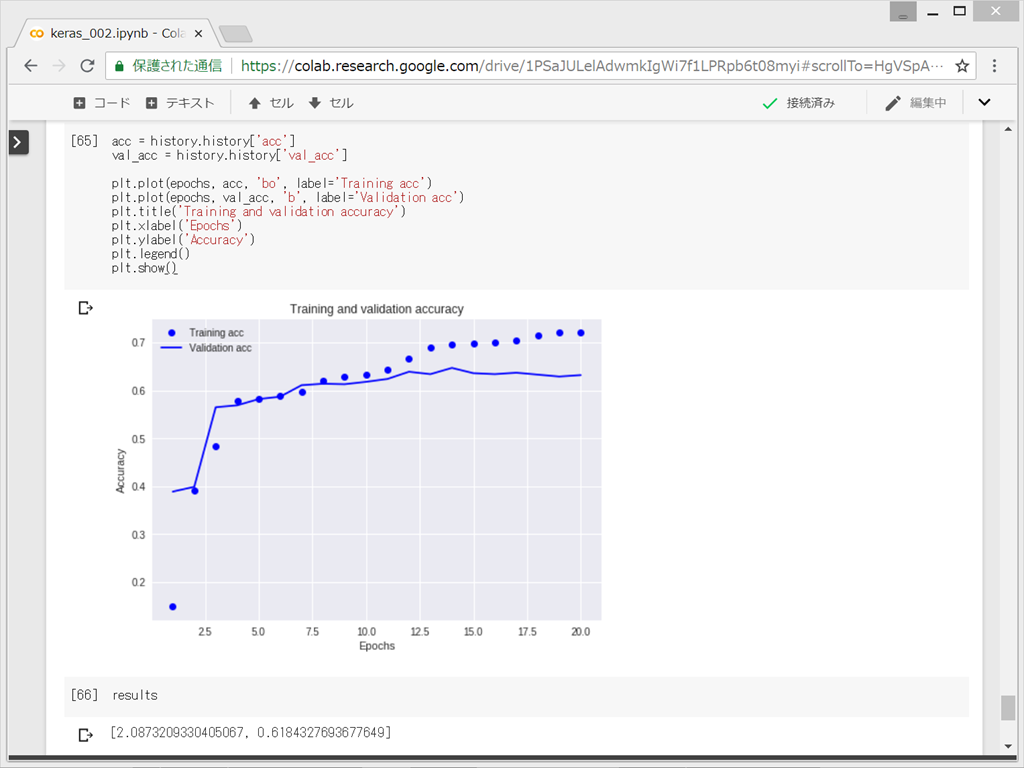
損失値と正解率をプロット
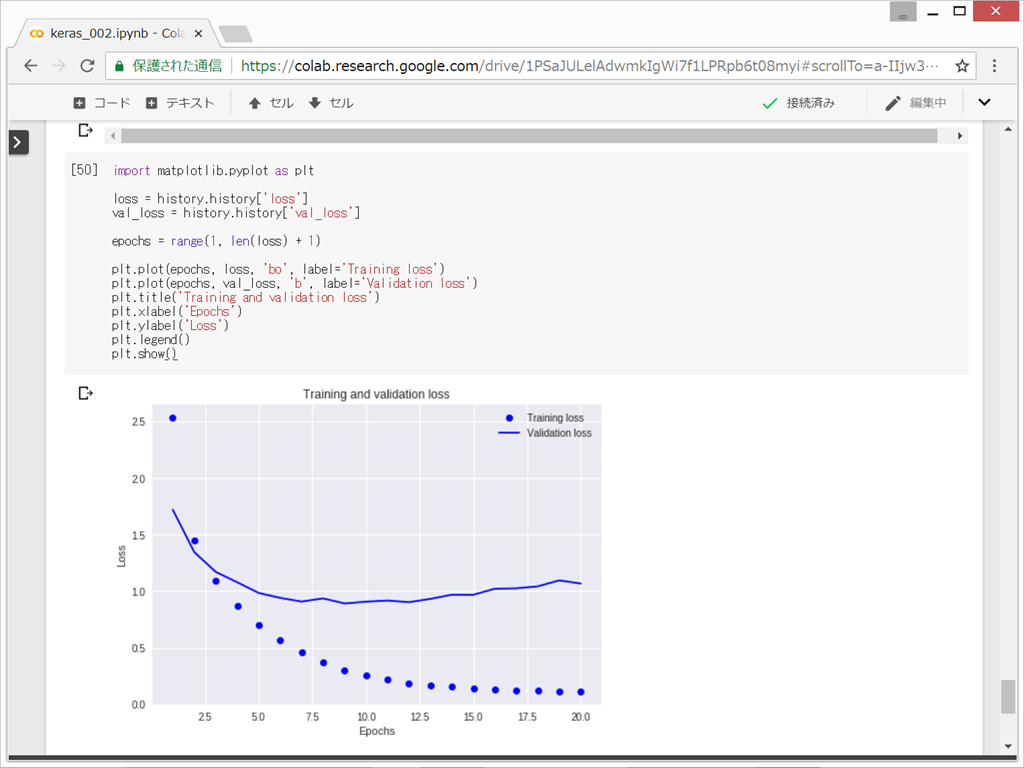{kind=link}
{kind=link}
過学習
{kind=link}
{kind=link}
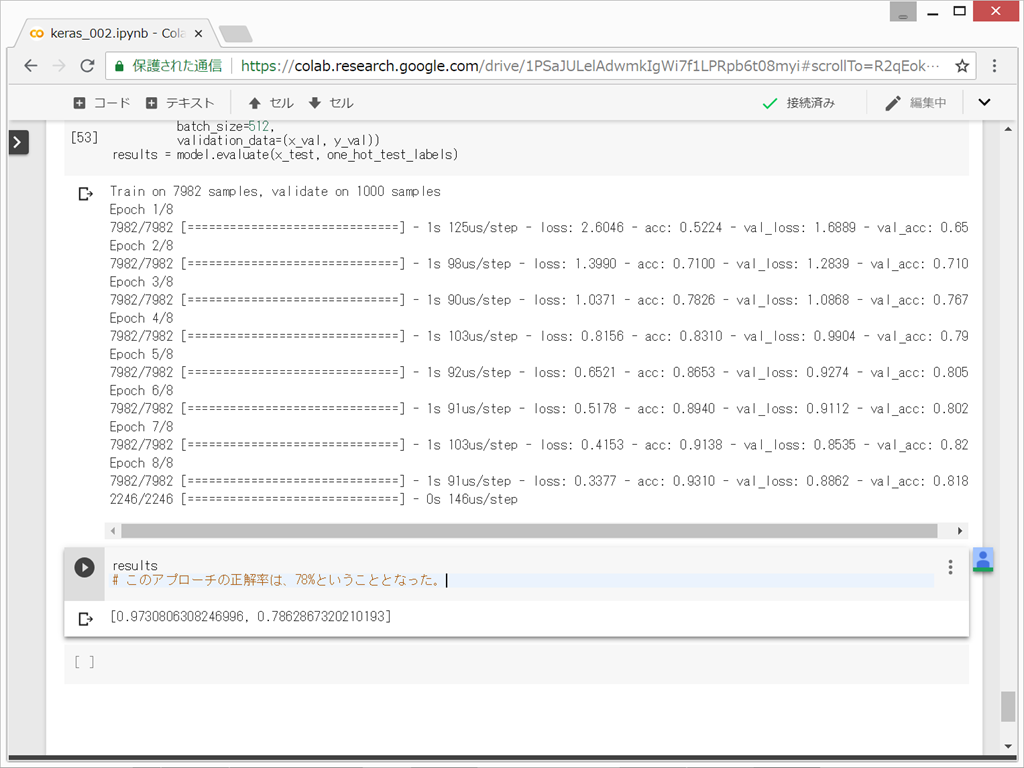
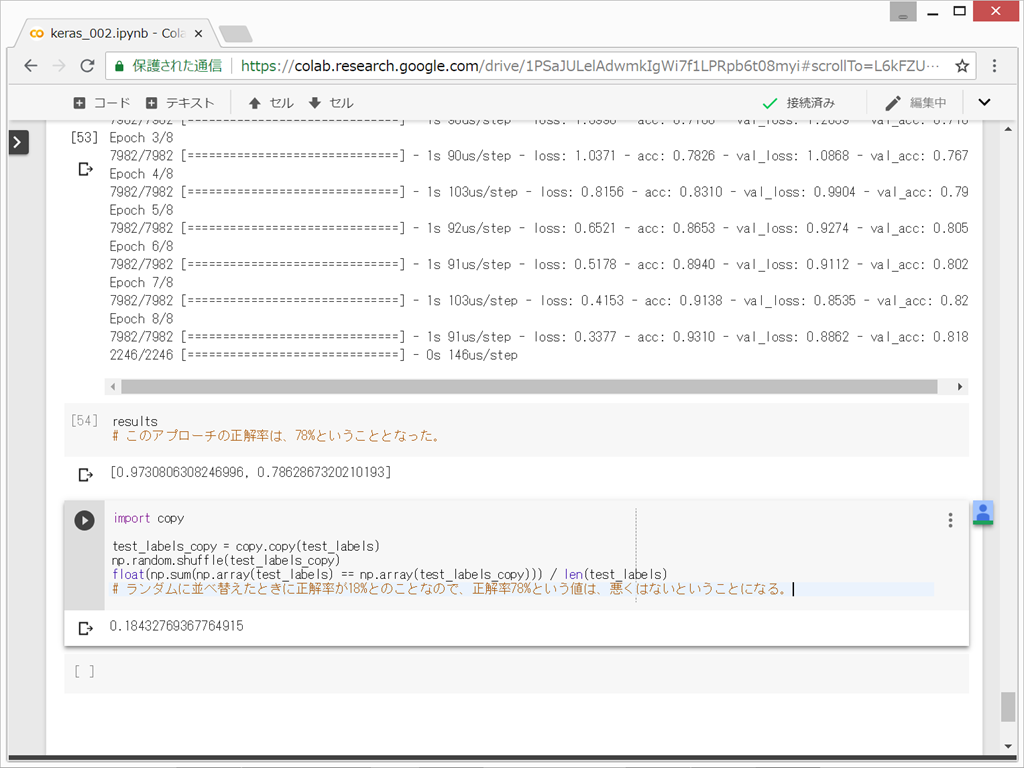
ランダムに並べ替えたときに正解率が18%とのことなので、正解率78%という値は、悪くはないということになる。
{kind=link}
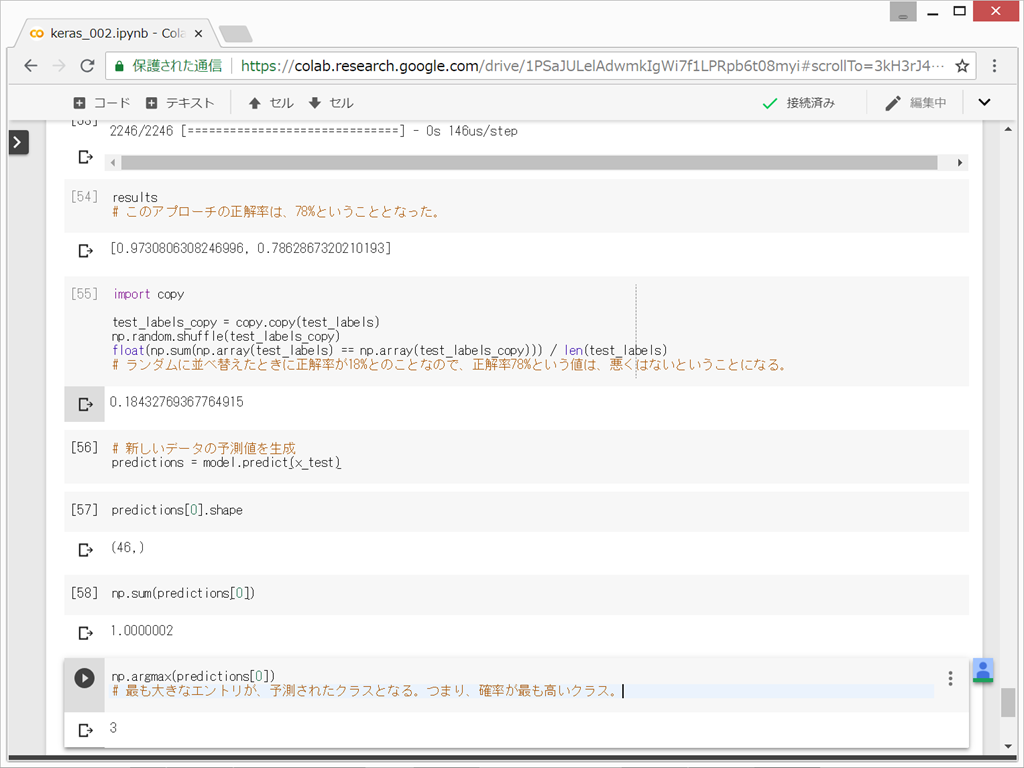
新しいデータで予測値を生成する
{kind=link}
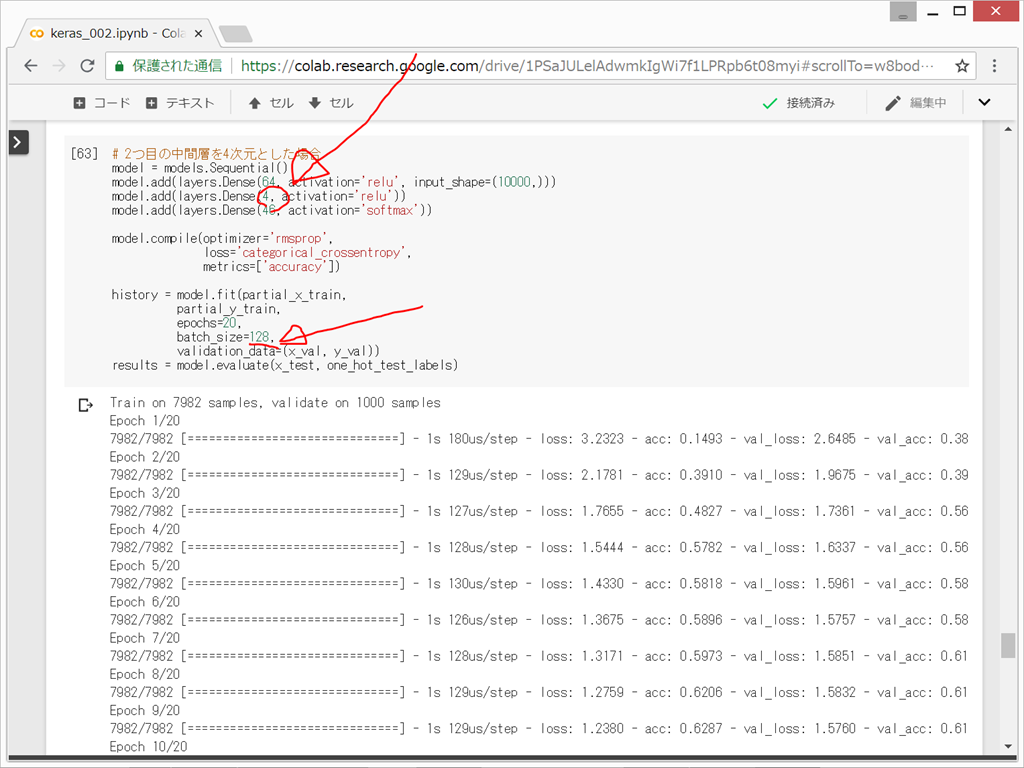
(7)十分な大きさの中間層を持つことの重要性
2つ目の中間層を4次元とした場合
{kind=link}
{kind=link}
{kind=link}
{kind=link}
「PythonとKerasによるディープラーニング」のp86では、正解率71%と書いてあったが、私の場合はもっと悪く、61%くらいであった。とにかく、中間層の次元が低すぎると、正解率が下がるということらしい。。。
(9)まとめ
データ点をN個のクラスに分類しようとする場合、ネットワークの最後の層は、サイズがNのDense層でなければならない。
多クラス単一ラベル分類問題では、ネットワークの最後の層の活性化関数としてsoftmaxを使用する。
損失関数は、categorical_crossentropy (多クラス交差エントロピー)を用いる。
<多クラス分類でラベルを扱う方法>
(1)カテゴリエンコーディング(one-hot encoding)を用いてラベルをエンコードし、損失関数としてcategorical_crossentropyを使用する。
(2)
今回もなかなか面白かった。初めて機械学習の勉強をするときにこの本「PythonとKerasによるディープラーニング」を読んでもさっぱり分からないかもしれない。しかし、「ゼロから作るDeep Learning」「ゼロから作るDeep Learning ❷」を何回も読んだ後、この本を読むと、簡潔にまとめられていて、よい復習になって、頭の中が整理されていきます。
次は、「PythonとKerasによるディープラーニング」の第3章の3.6 回帰の例:住宅価格の予測 を写経してみたいと思います。