「Rによる統計解析」を写経してみる(2)
衝動買いしてしまった以下の本。結構分かりやすくて面白い。
これ、Rの名著だと思います。EZRが扱えるようになって、自分でRを使ってグラフを描いたり、いろいろやってみたい方に、一番お勧めの本です。
前回は、第2章の一部を写経してみた。
http://twosquirrel.mints.ne.jp/?p=21183
今回は、第3章を、写経してみたい。
(環境)
Windows 8.1 Pro
Anaconda 4.4.0 (64-bit)
(1)データの作成
このサイトが超便利!
{kind=link}
「生成を開始する」をクリックして、適当に条件を決めて、生成開始 をクリック
{kind=link}
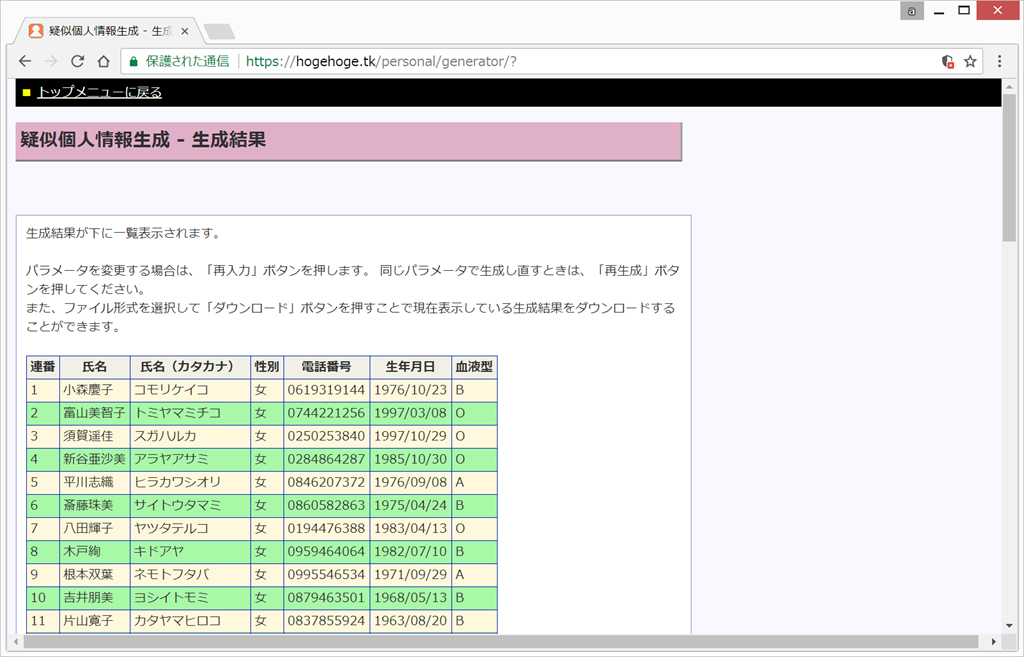
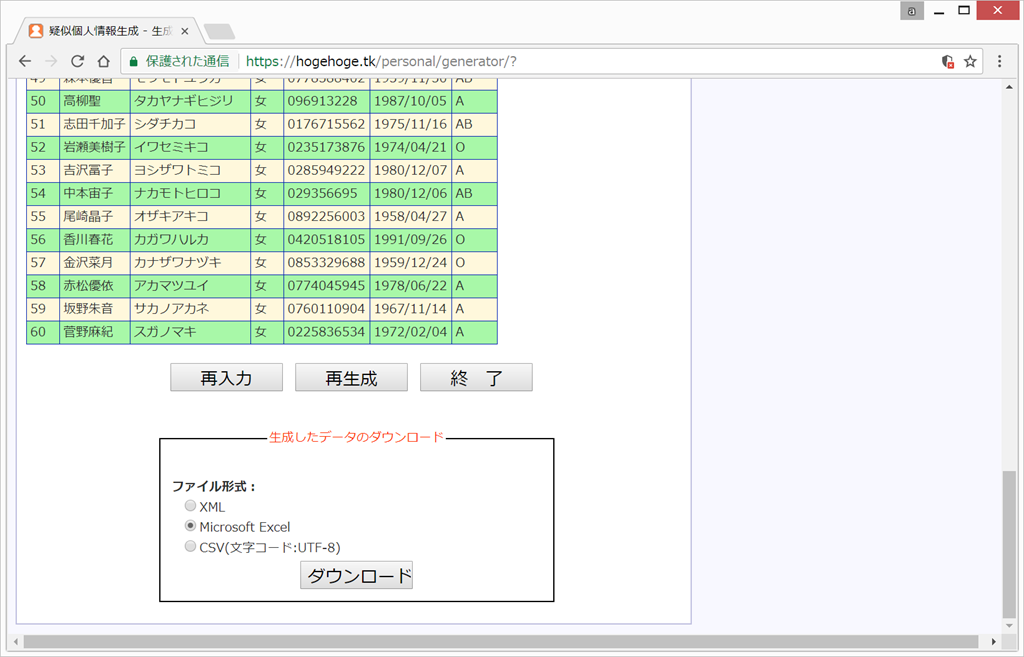
以下のように出てくるので、下の方へ行って、エクセル形式でダウンロード
{kind=link}
{kind=link}
{kind=link}
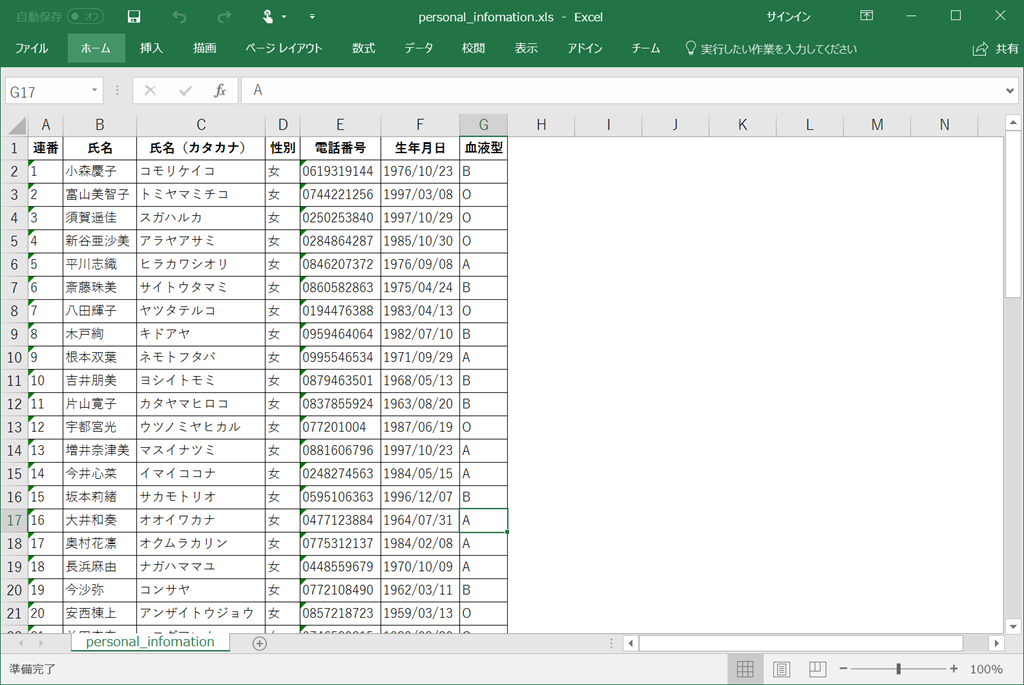
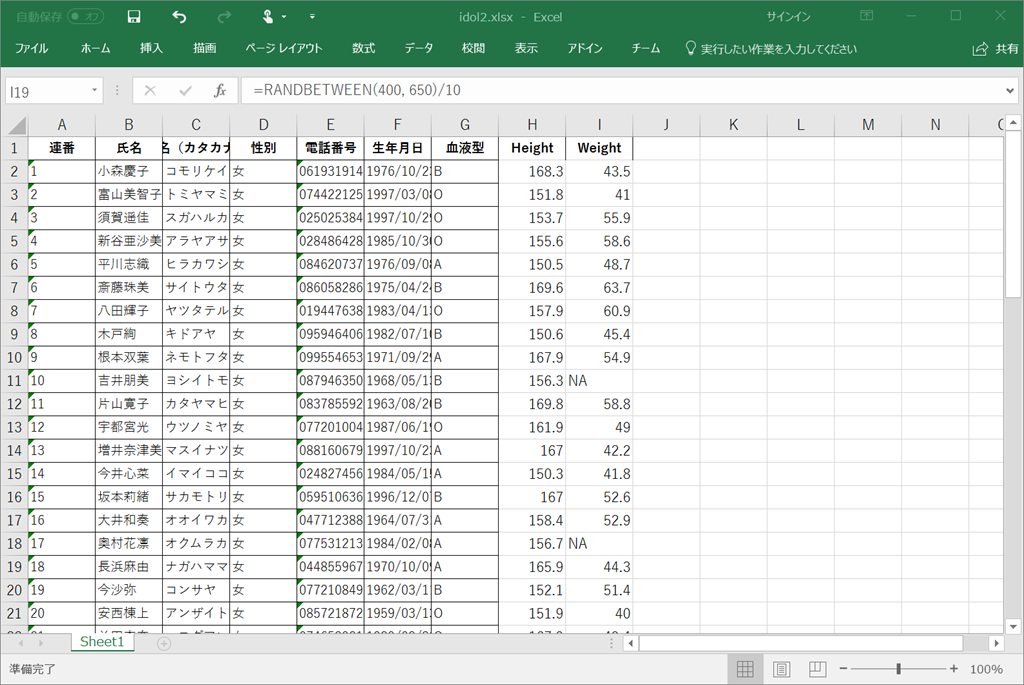
新しいエクセルファイルを作成してコピペして、WeightとHeightを適当に生成。
=RANDBETWEEN(“最小値", “最大値") というエクセル関数を使用した。
ABO型もこれと似たようなエクセル関数で最初から作成できたような、、、(爆)
でも、上記サイトは非常にありがたいサイトです。
参考:https://dekiru.net/article/4390/
{kind=link}
{kind=link}
idol.csvという名前で保存。
{kind=link}
(2)(1)で作成したidol.csvと同じフォルダに、新しいipynbファイルを作成し、chapter02 という名前をつけた。
#3.1 データを要約する # summary(データフレーム名)
df <- read.csv(“idol.csv")
df
{kind=link}
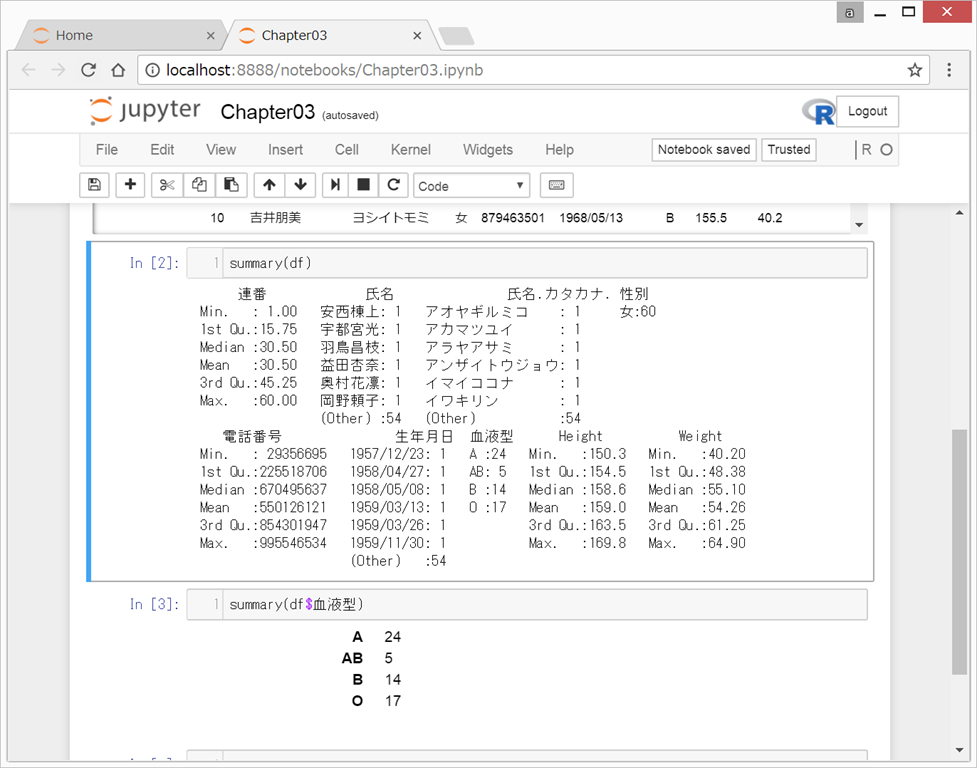
summary(df)
{kind=link}
summary()関数は、平均値、最大値、最小値をさくっと出してくれるので便利である。
(3)グループ別にデータを要約
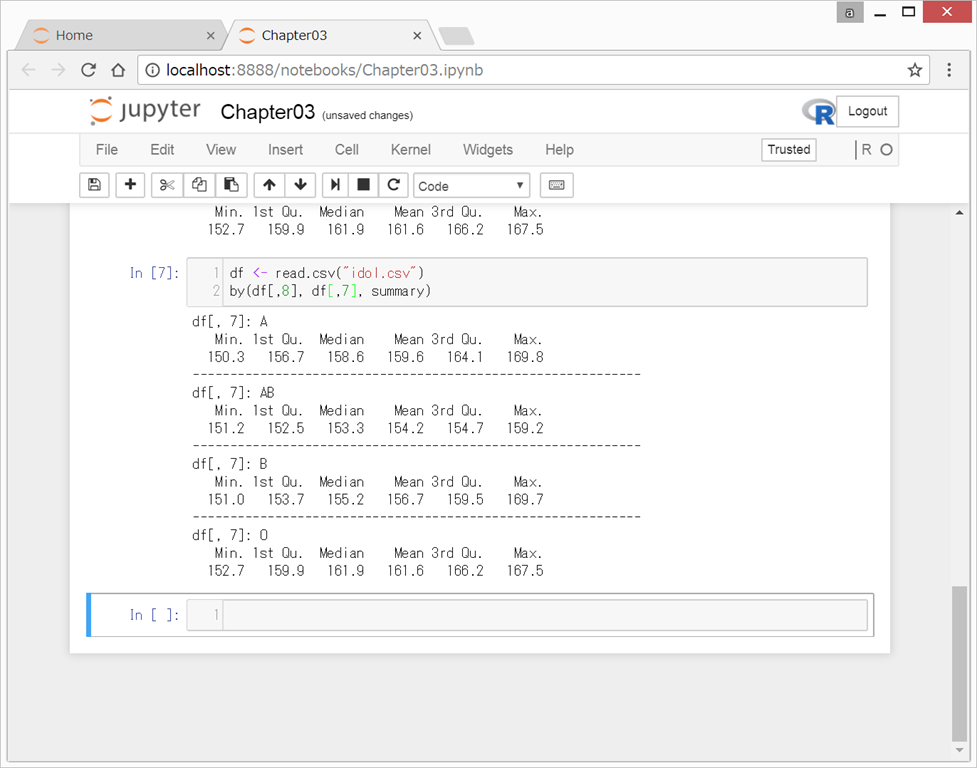
tapply(“対象変数", “グループ変数")
by(“対象変数", “グループ変数")
のように用いるらしい。これも、男性と女性それぞれの年齢の平均など求めるときに便利そう!
{kind=link}
{kind=link}
(4)基本統計量を求める
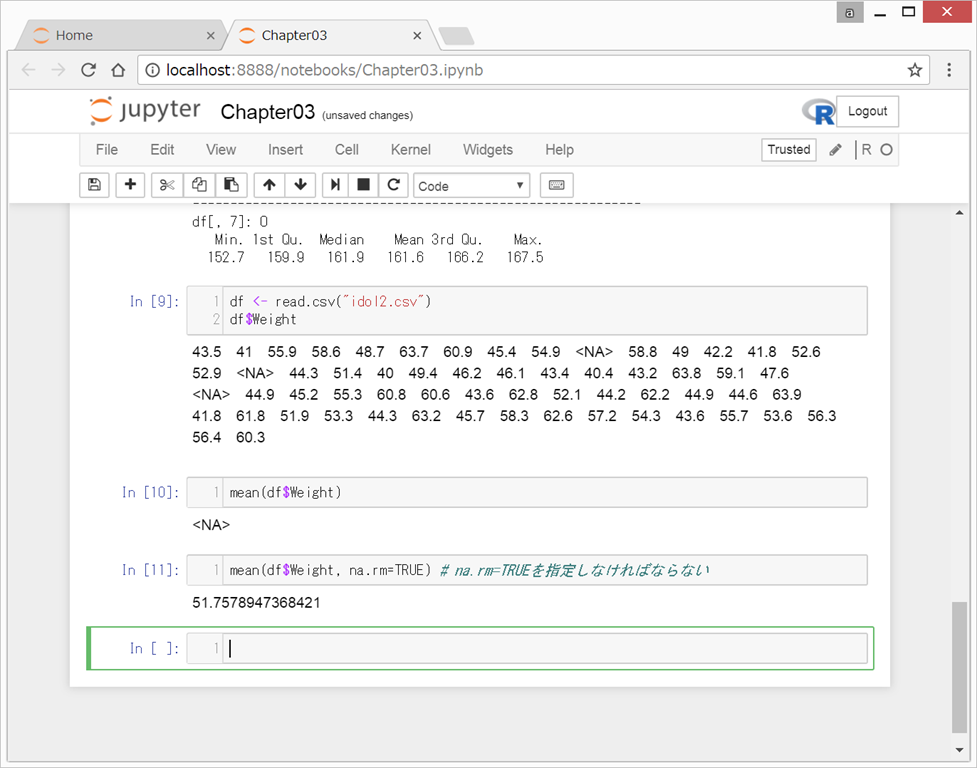
NAを持つデータを除いて集計するためには、引数に
na.rm=TURE
を指定しなければならない。
{kind=link}
{kind=link}
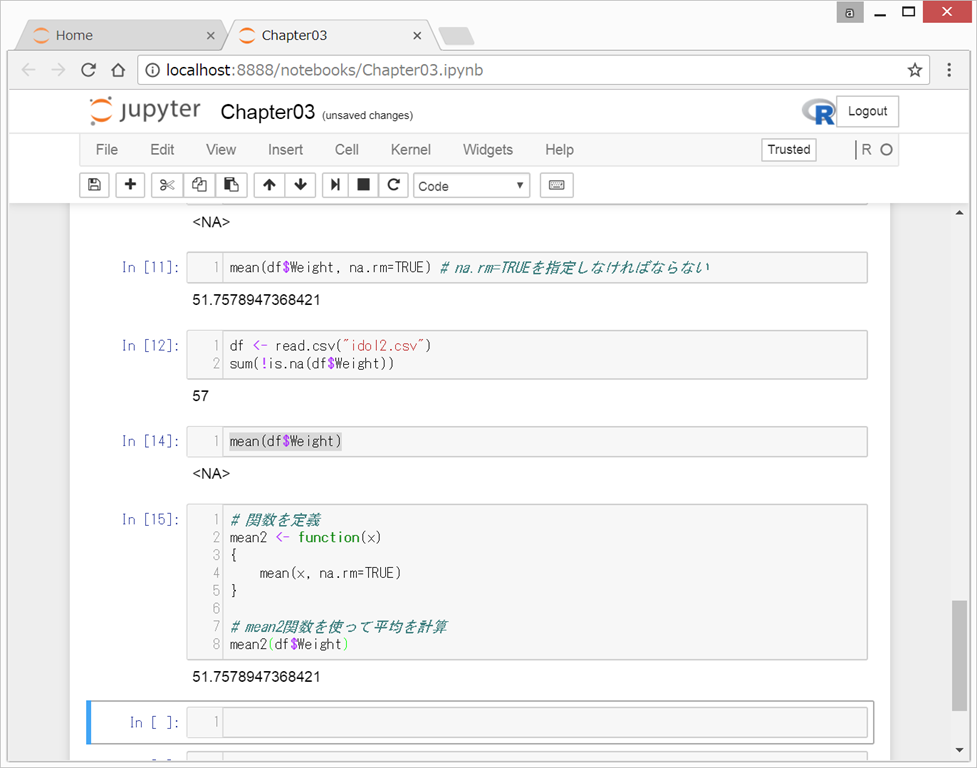
df <- read.csv(“idol2.csv")
df$Weight
mean(df$Weight)
mean(df$Weight, na.rm=TRUE) # na.rm=TRUEを指定しなければならない
{kind=link}
有効データ数
count <- function(x) sum(!is.na(x))
新しい関数の定義と利用
# 関数を定義
mean2 <- function(x)
{
mean(x, na.rm=TRUE)
}
# mean2関数を使って平均を計算
df <- read.csv(“idol2.csv")
mean2(df$Weight)
{kind=link}
また、必要に応じて、グラフはかけるようになっていきたい。
なお、散布図についてのリンク
http://aoki2.si.gunma-u.ac.jp/R/dot_plot.html
{kind=link}
{kind=link}
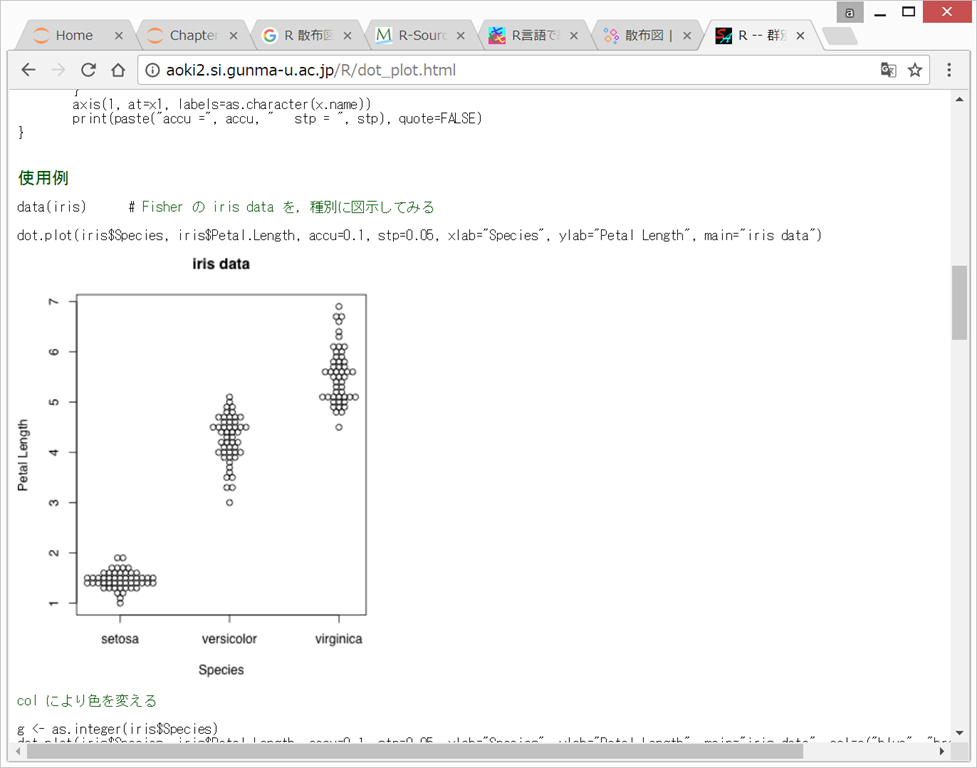
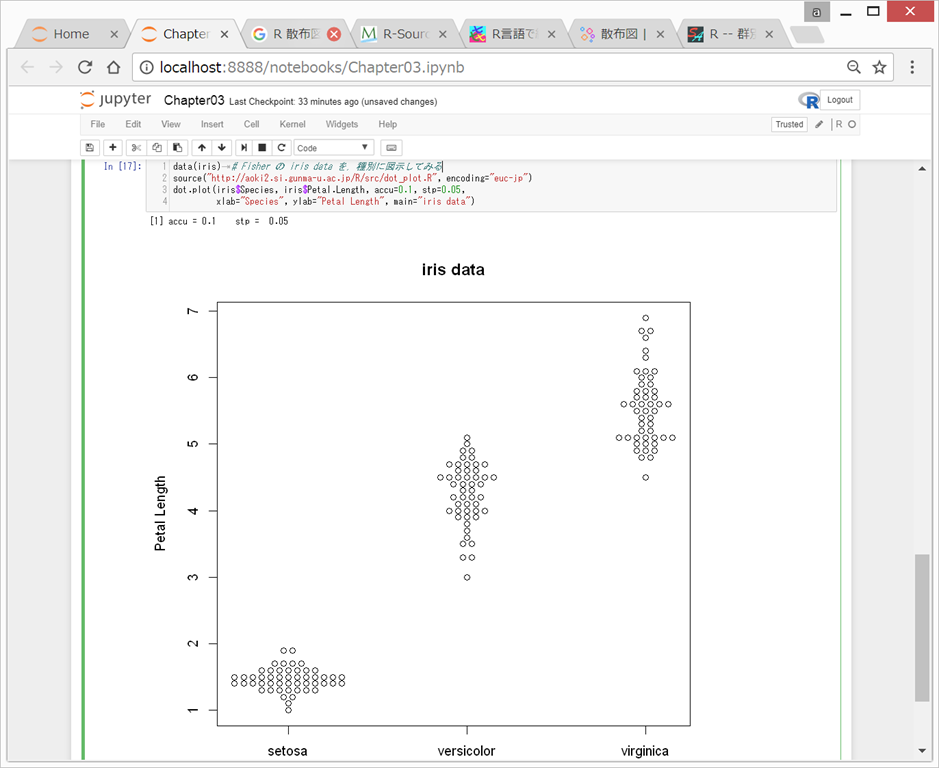
dot.plot関数というものを用意してくださっており、それをjupyter notebookで利用すると、以下のようになる。
{kind=link}
これは便利!このような素晴らしいサイトが、EZR誕生の流れになったのだなあと勝手に感動してしまいました。