【初めてのChatGPTその2】ChatGPT関連の用語集
![[岡野原 大輔]の大規模言語モデルは新たな知能か ChatGPTが変えた世界 (岩波科学ライブラリー)](https://m.media-amazon.com/images/I/51FEIh-Om1L.jpg)
ChatGPTはLLM(大規模言語モデル)の一種だそうです。
transformerというDeep Learningモデル(機械学習モデル)に、超大量の文章を読み込ませまくって、学習させ、それをもとに、修正して作成した人工知能(AI)が、ChatGPTだそうです。
「大規模言語モデルは新たな知能か ChatGPTが変えた世界(2023年)」は、ChatGPTが全く分からない人向けに、その原理から
- ChatGPTとはいったい何なのか?どのようにして作られたのか?(数式無しで説明)
- ChatGPT使用の際の注意点
について、腰を据えてしっかり説明してくれています。その中でも、気になった単語について、以下に列挙したいと思います。
- AI(人工知能 Artificial Intelligence)
- 機械学習 (Machine Learning)
- ディープラーニング (Deep Learning)
- 生成AI (Generative AI) → 生成 AI とは?
- 大規模言語モデル (Large Language Models、LLM)
- ChatGPT
- 幻覚(ハルシネーション Hallucination) → ハルシネーション(Hallucination)とは?
- プロンプト
- 創発
AI, ML, DL, Generative AI
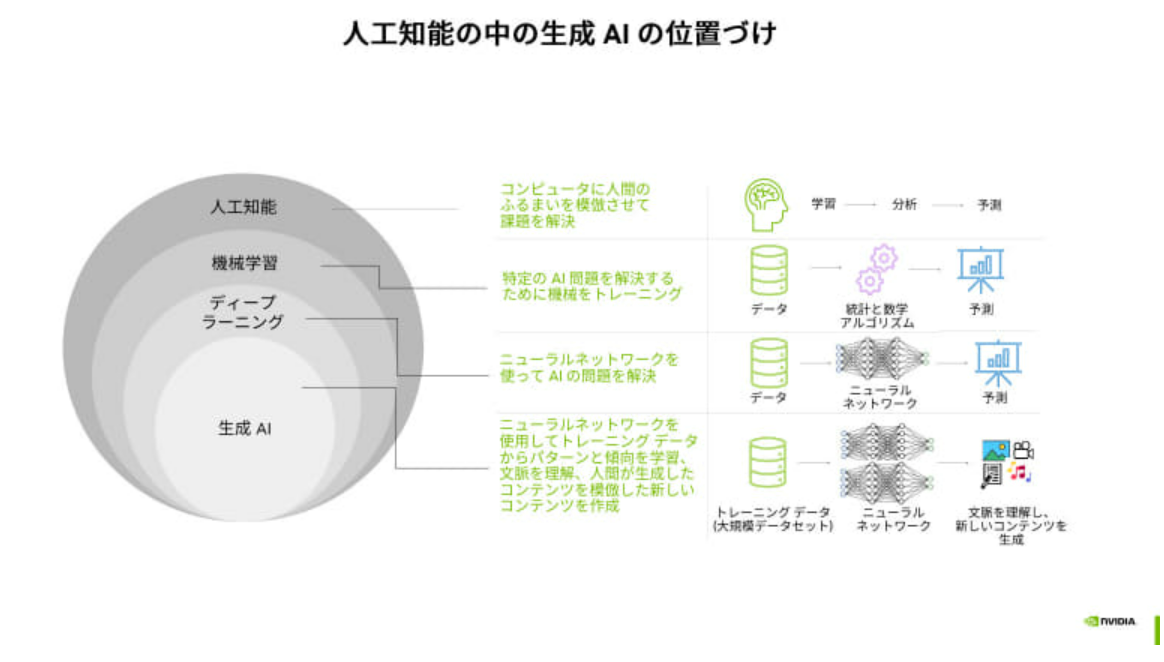
AI(人工知能 Artificial Intelligence)
人工知能とは、人間の知的能力をコンピュータ上で実現するプログラムである(Wikipedia)。
機械学習 (Machine Learning)
機械学習とは、経験からの学習により自動で改善するコンピューターアルゴリズムであり、人工知能AIの一種である。「訓練データ」もしくは「学習データ」と呼ばれるデータを使って学習し、学習結果を使って何らかのタスクをこなす。(Wikipedia)
ディープラーニング (Deep Learning)
ディープラーニングとは、機械学習のうち、ニューラルネットワークを用いて大量の「学習データ」をもとに機械学習を行う手法である。(Wikipedia)
生成AI (Generative AI)
生成AI(生成的人工知能、generative artificial intelligence)とは、プロンプトに応答してテキスト、画像、または他のメディアを生成することができる人工知能システムの一種である。生成AIモデルは、入力された訓練データの規則性や構造を学習し、同様の特性を持つ新しいデータを生成する(Wikipedia, 生成 AI とは?)。2022年11月にOpen AI社より発表された、ChatGPT(非常に優秀なチャットボット)は、テキストを入力すると、テキストを出力するが、解答が非常に優秀であり、生成AIを世に知らしめるきっかけとなりました。
大規模言語モデル (Large Language Models、LLM)
大規模言語モデルとは、大規模コーパス(文章)で事前訓練された、数百万から数十億以上のパラメータを持つディープラーニングモデルをのことです(Wikipedia)。ChatGPTは大規模言語モデルのうちの一つです。
幻覚(ハルシネーション Hallucination)
{kind=link}
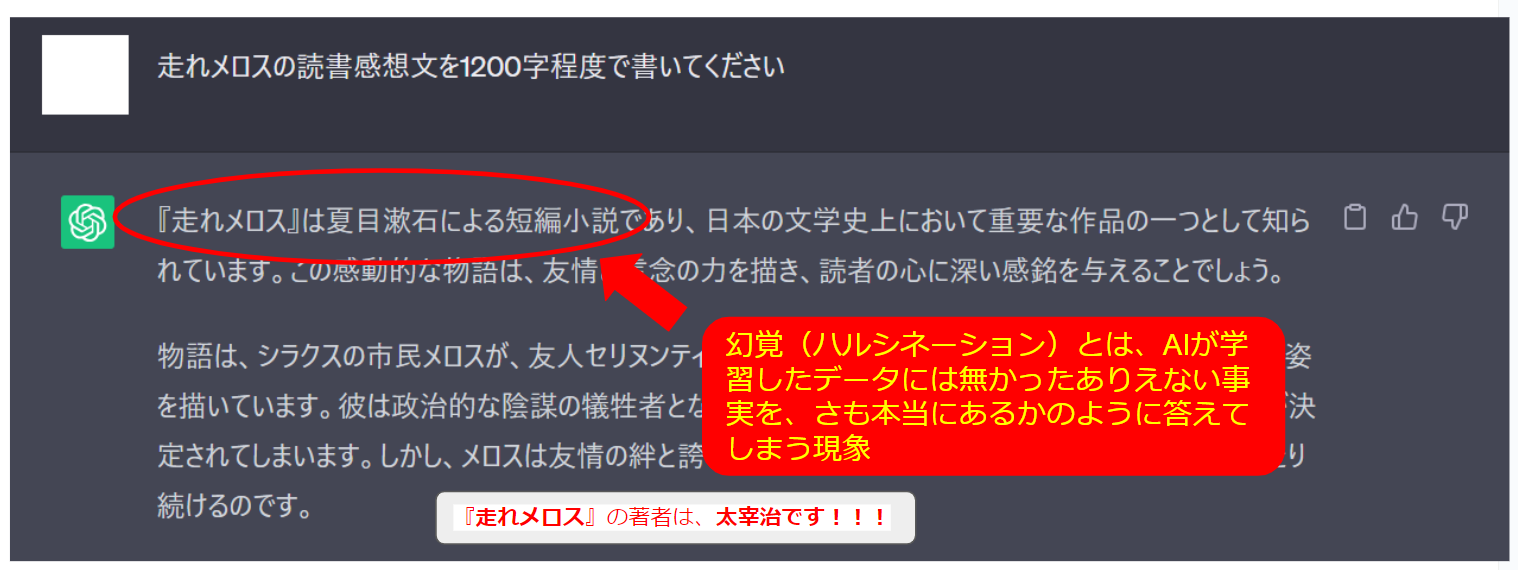
幻覚(ハルシネーション)とは、ChatGPTなどの大規模言語モデルにおいて、学習したデータには無かったありえない事実を、さも本当にあるかのように答えてしまう現象のことである。
上の画像でも、ChatGPTは、「走れメロス」の著者が夏目漱石と言っていますが、本当の著者は、太宰治(だざいおさむ)です[Wikipedia]。このように、堂々と、大嘘を言われてしまうことがよくあります。複数行の足し算や、小学生でもわかるような基本的な物理的事実なども、間違えることがあるとのことです。そのため、ChatGPTが示す結果をそのまま信用してはいけない
となります。事実関係については、Google検索や本などで、自分でチェックする必要があります。または、ChatGPTでも、Bing AIで引用されているソース(情報源)をチェックするのもお勧めです。
なぜこのような「幻覚」が起こるのかというと、ChatGPTが行っていることは、
- 世の中に存在する膨大な文章をもとに、
- 入力されたプロンプトを文脈として、その後に続く単語を予測する
- そして、生成した単語のさらに後に続く単語を予測する
- 上記を繰り返す
だけであるためであるらしい。
プロンプト

ChatGPTに指示する文章を「プロンプト」と呼びます。
「スマホアプリ対応版 ChatGPTの応答精度はプロンプトが9割」によると、
「ChatGPTをうまく利用できるかどうかは、プロンプトの書き方が全て!」
だそうなので、
良いプロンプトの書き方
を、腰を据えて勉強するしか無さそうです。
プロンプト(指示)は、正確であり、詳細を含むほどよく、業務委託における指示書を作成するようなものとのことです。例えば、
「あなたはプロの編集者です。次の文章を編集してください」
のように書くのがよいそうです。
創発(Emergence)
ChatGPTのモデルのパラメータ数は、
- GPT-1 (2018) 1.2億(パラメータ数)
- GPT-2 (2019) 15億
- GPT-3 (2020) 1750億
- GPT-4 (2023) (おそらく、数千億から数兆)
のように、年々莫大に増えています。
2023年現在、「モデルサイズを大きくすれば学習効率が上がる」(同じ投入計算量であればモデルサイズが大きい方が、より効率的に学習できる)ということがわかりました。
さらに、モデルサイズを大きくしていく中で、それまでまったく解けなかった問題が、ある時点から急に解けるようになる現象が見つかり、これを、「創発(Emergence)」と呼ぶようになったとのことです。
「数は力」
だそうです。でも、これだと、資金力のある会社に利益が独占されてしまいそうで、すごく怖いでと思いました。
トランスフォーマー Transformer
トランスフォーマー(Transformer)とは、ディープラーニングのモデルのうちの一つであり、ChatGPTはこのモデルを用いています。Transformerは、RNN(リカレントニューラルネットワーク Recurrent Neural Network)やLSTM(Long Short-Term Memory: 長・短期記憶)の後継モデルと考えることができます。
データの流れ方の動的な制御を実現する仕組みの一つとして、「注意機構 Attention」がある。注意機構は、言語モデルにおいて、次に出現するであろう単語を予測するために、過去の単語列から必要な情報を選択することに用いられる(どの言葉に重点的に着目するかを決める)。
「自己注意機構」は、「過去の自分の途中処理結果」を注意対象とする機構である。
本文中(In-Context)学習
本文中学習とは、あらかじめ訓練データで学習したのとは別に、今処理している中で学習していくこと(例:「あなたはプロの編集者です。」)
大規模言語モデル(ChatGPT)は、利用時にはパラメータは固定である。
しかし、「自己注意機構」によって、重みパラメータを一時的に変えているとみなすことができ、あたかもパラメータを変えて学習した場合と同様に、指示や、今生成しているデータにあわせて、モデルを急速に適応させていく。
自己注意機構は、もともと、遠くの文脈も利用できるという目的で導入したが、結果、以下のように、「メタ学習」を実現することになった。
メタ学習
複数のタスクを学習することで、学習方法自体を学習させることをメタ学習と呼ぶ。
言語モデルと自己注意機構の組み合わせは、メタ学習を実現した。
前もってすべての状況に対応できるようにすることをあきらめ、代わりに、その場で(プロンプトで指示したり、自分で生成した文章を見た結果で、)適応する能力を獲得することで、「汎化」することを実現できるようになった。まだ見たことがないデータであっても、その場で適応することができるようになった。
汎化
汎化(はんか)とは、機械学習モデルが未知のデータに対応できる能力のことである。
学習データの答えに特化して覚えて(モデルのパラメータの変更)しまい、未知のデータに対応できなくなることを「過学習」と呼ぶ。
破壊的忘却
破壊的忘却とは、機械学習モデルが、新しいことを覚えたりすると、以前覚えたことを忘れたり、壊したりしてしまう現象のことである。
RLHF(目標駆動学習、人間のフィードバックによる強化学習)
「強化学習」とは、行為者が環境と相互作用しながら次々と行動をとっていくような問題で現在の状態に応じて報酬が得られる場合に、受け取る報酬の合計値を最大にする行動をとれるようにする学習方法である[大規模言語モデルは新たな知能か ChatGPTが変えた世界(2023年)]。
ChatGPTでは、プロンプトを与え、
- 嘘をついていないか(真実性)
- 有害でないか(無害性)
- ユーザーに役に立つか(有益性)
などを、ラベラーと呼ばれる人が評価して、このフィードバックを使って、言語モデルを強化学習で修正していく。これを、目標駆動型学習RLHFと呼ぶ。
ChatGPTが得意とする場面
以下のようなことが得意だそうです。
- 文書の校正・要約・翻訳 → 人間には読み切れないような大量の文章や、複数文書の情報を効率的にまとめることも可能
- プログラミングのサポート → 回答結果が100%正確である保証はないが、かなり便利らしいです
- WEB検索の代わり → 最初にChatGPTである程度調べて、出てきた単語は自分でGoogle検索でファクトチェックが必要そうです
- 言語を使った作品を作る → 読書感想文、日記、履歴書、小論文、歌詞、論文の文章作成。ブレインストーミング用のアイデアを瞬時にたくさん出してもらうなど便利。もちろん、幻覚(ハルシネーション)のリスクがあるので、ファクトチェックは必要
- 言語以外を使った作品を作る → 大規模言語モデルと他のモデルを組み合わせて、画像、音声、動画を作れるそうです
- カウンセリング、学習のサポート
- 高度な専門性が必要な仕事のサポート → 士業職、医療、金融、健康などの専門家が提供していた情報サービスを、ChatGPT(大規模言語モデル)から得ることができるようになる未来がすぐそこまで