ELISAの測定結果からサンプルのタンパク質濃度をRを用いて計算する
以下のサイトを写経して、ELISAの計算の練習をしてみたいと思います。
https://www.pediatricsurgery.site/entry/2017/01/30/202953
2017-01-30
ELISAの測定結果をRで計算する 2. 4パラメーターロジスティック回帰で吸光度から濃度を求める
開発環境
Windows 10 Pro (1803)
R 3.5.3
RStudio 1.1.463蛇足ですが、ちょっとスピードがゆっくりですが、
https://rstudio.cloud/
というサイトが、2019年9月現在、メールアドレスとパスワード登録だけで無料で使用することができます。便利です。
新規RNotebookの作成と保存
RStudioを起動し、File > New File > R Notebook の順にクリックして、新規RNotebookを作成します。
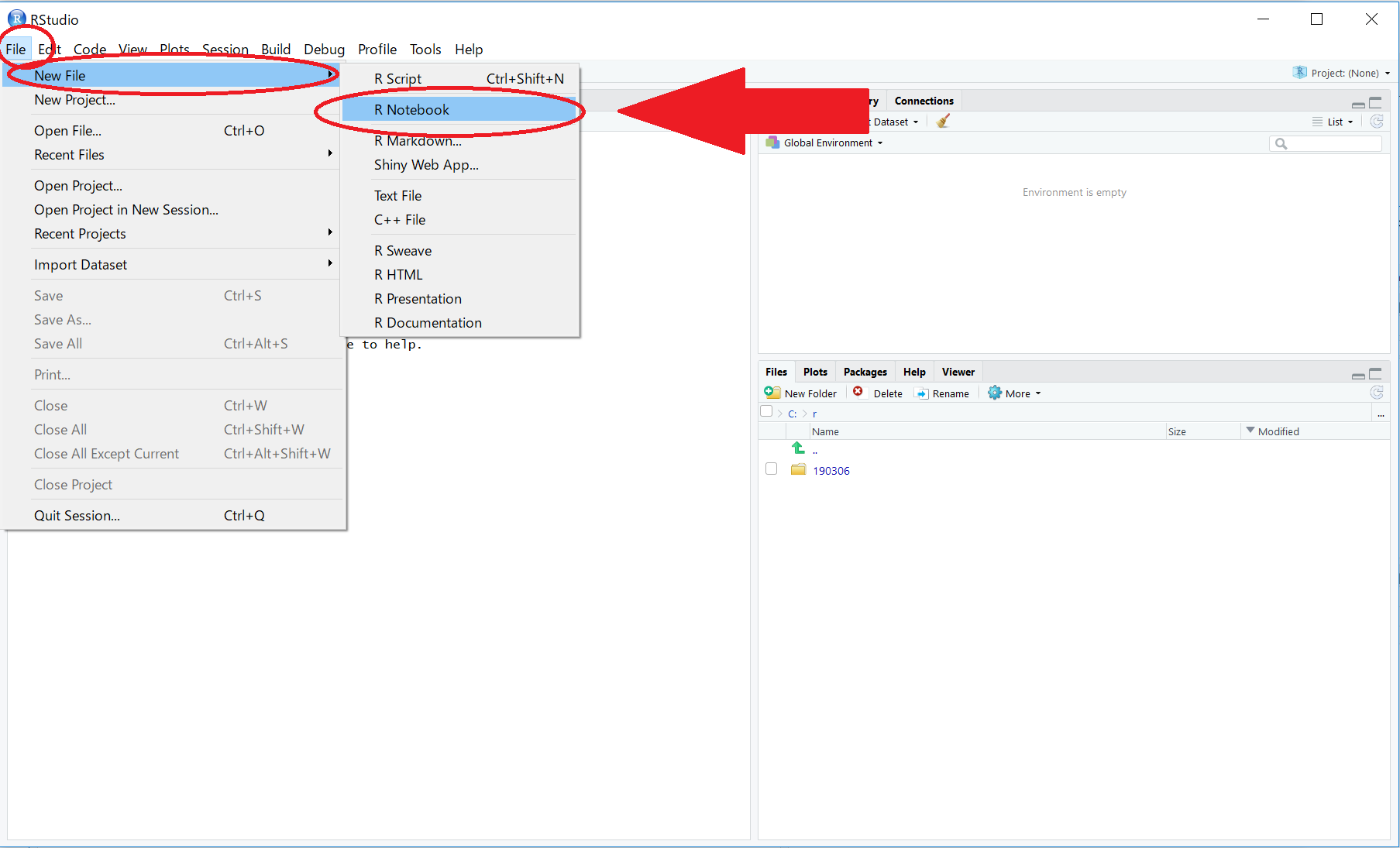
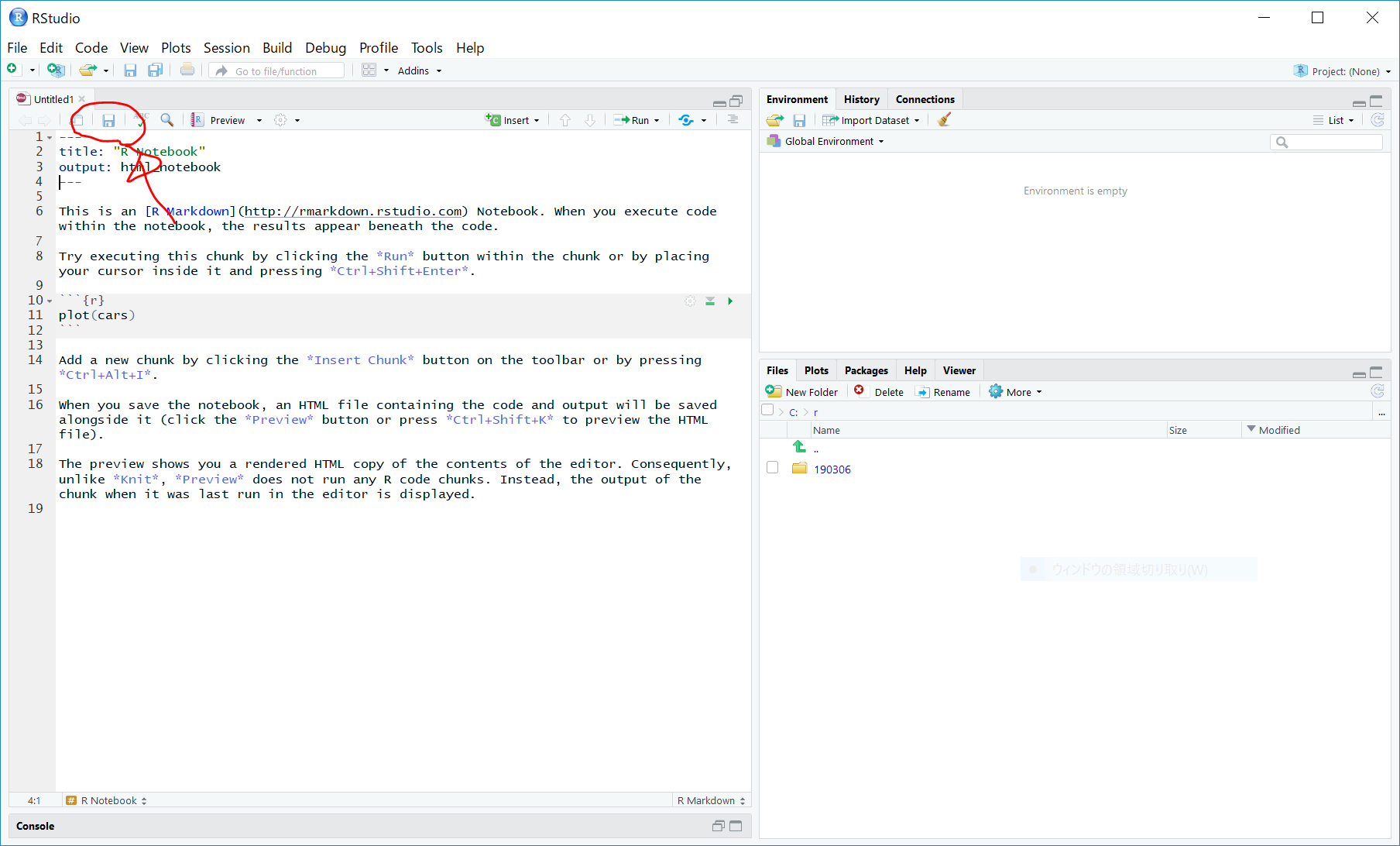
図の『保存アイコン』をクリックして、RNotebookを保存します。
C:/r/ フォルダに、190929_elisa_001 という名前で保存します。
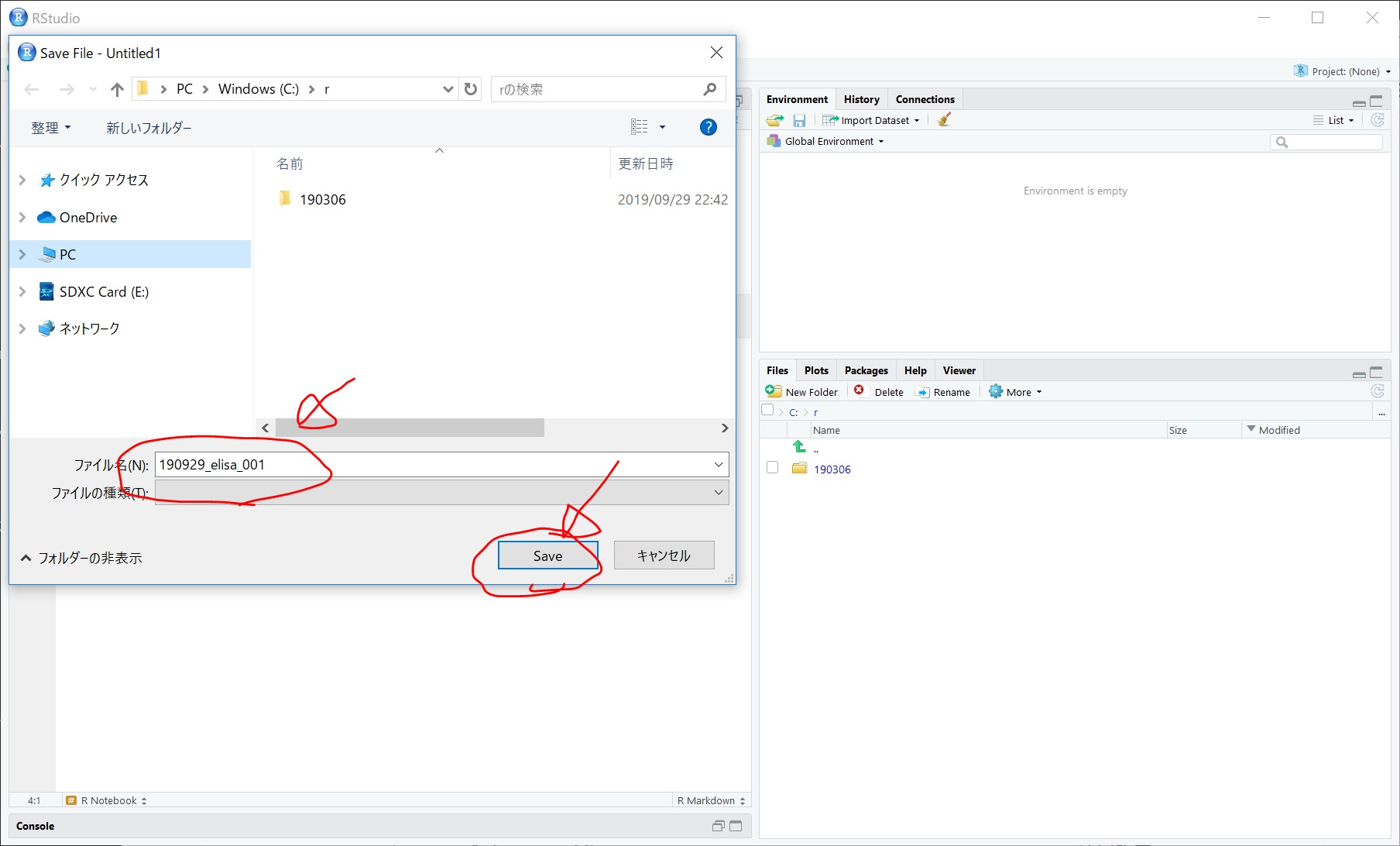
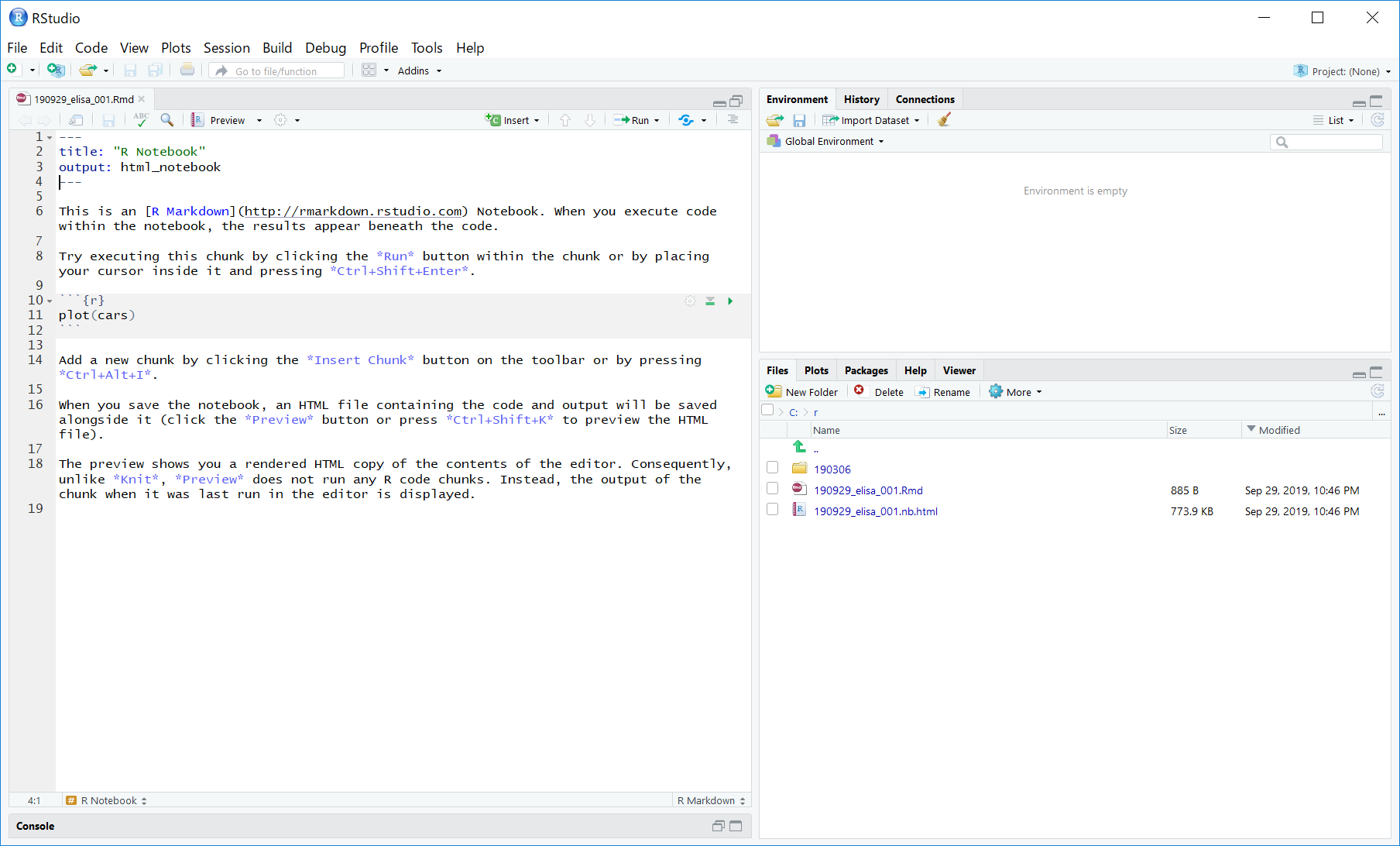
なお、以下の図を参考に、画面右下の “Files"タブで、C:/r/ フォルダを表示した状態にします。
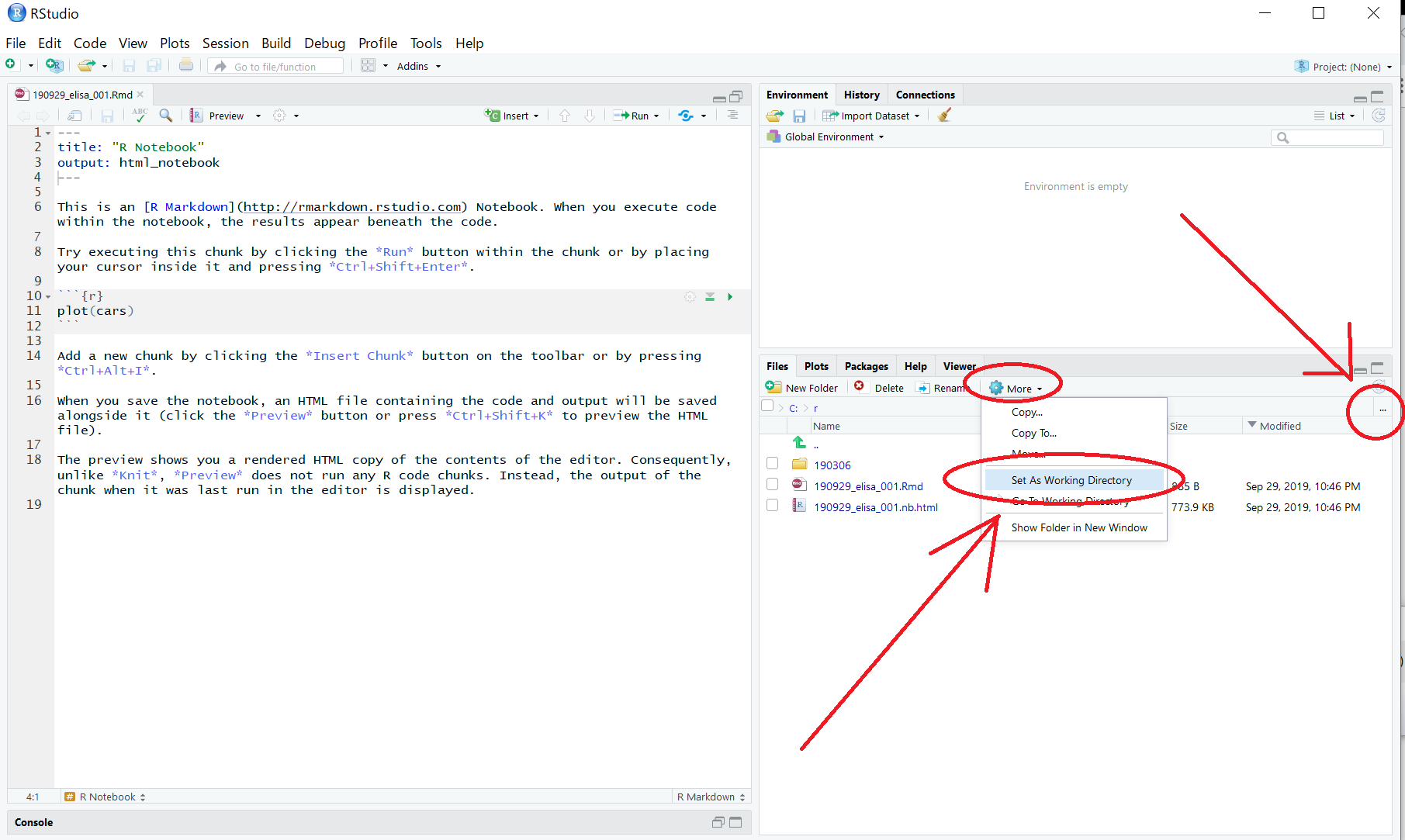
また、その画面で、More > Set As Working Directory をクリックし、画面左下のConsoleの中で、"setwd(“C:/r")" を実行しておきます。
tidyverse, drc, nplrパッケージのインストール
今回必要になる3つのパッケージをインストールします。
- tidyverse
- drc
- nplr
RStudio左下のConsole画面に以下を入力します。
install.packages("drc", dependencies = TRUE)
install.packages("nplr")
install.packages("tidyverse")
ELISAデータ(疑似データ)をGItHubから入手する
写経元サイトの管理者さまが用意してくださったデータをダウンロードします。自分で実験したときは、ELISAの測定結果をcsvファイルにして、read.csv()関数で、取り込みます。
(参考: https://to-kei.net/r-beginner/r-2/ )
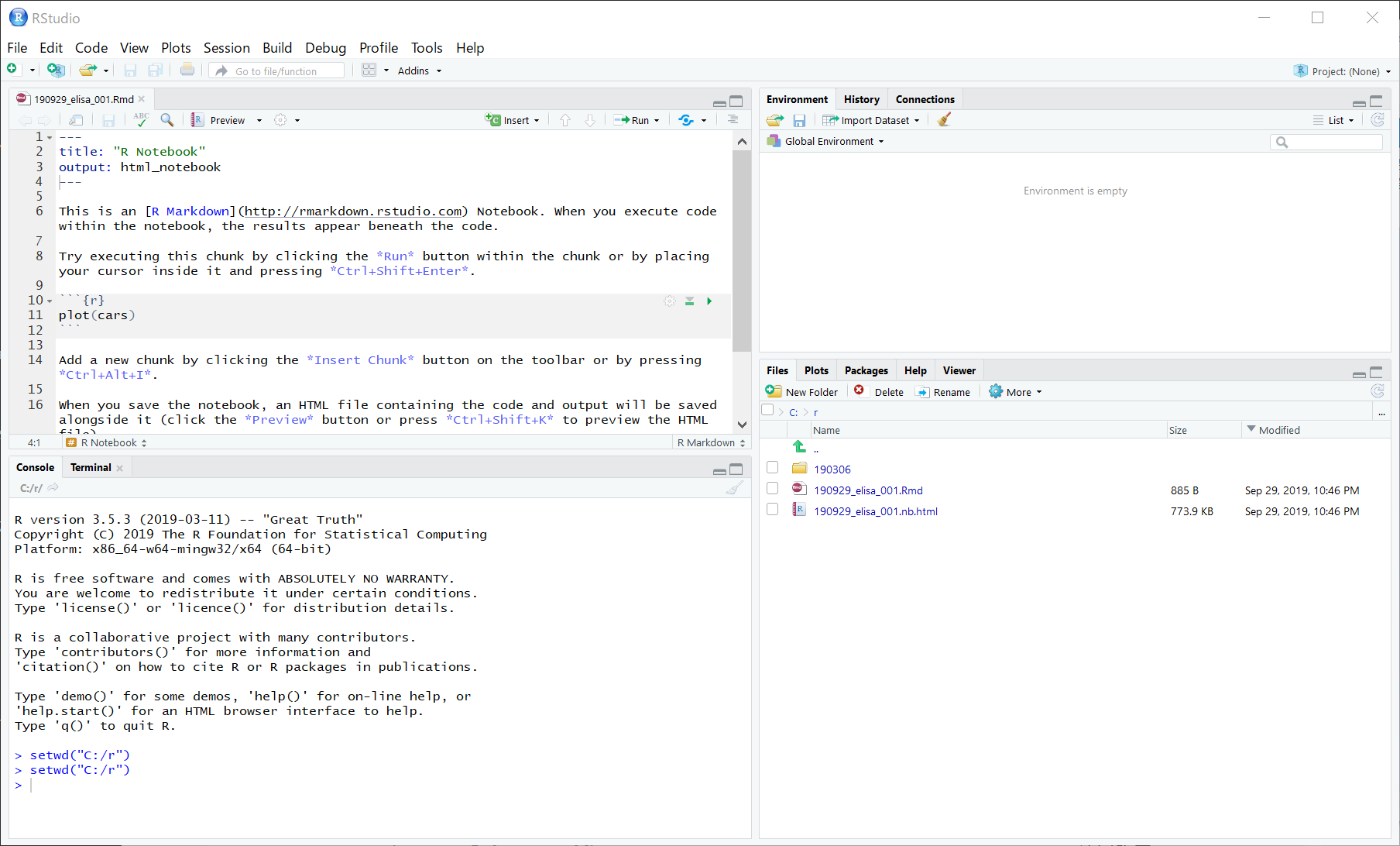
まず、画面左下のConsoleに以下を入力してRCurlパッケージをインストールします。
install.packages("RCurl", dependencies = TRUE)
次に、画面左上のRNotebookの画面、今回は、190929_elisa_001.Rmd となっているところの、グレーになっている、
plot(cars)
のところを以下のように書き換えます。
library("RCurl")
getURL("https://raw.githubusercontent.com/Razumall/NOPS/master/Data/ELISA.csv") %>%
read.csv(text = ., header = TRUE) %>%
tbl_df() -> df(変更前)
(変更後)
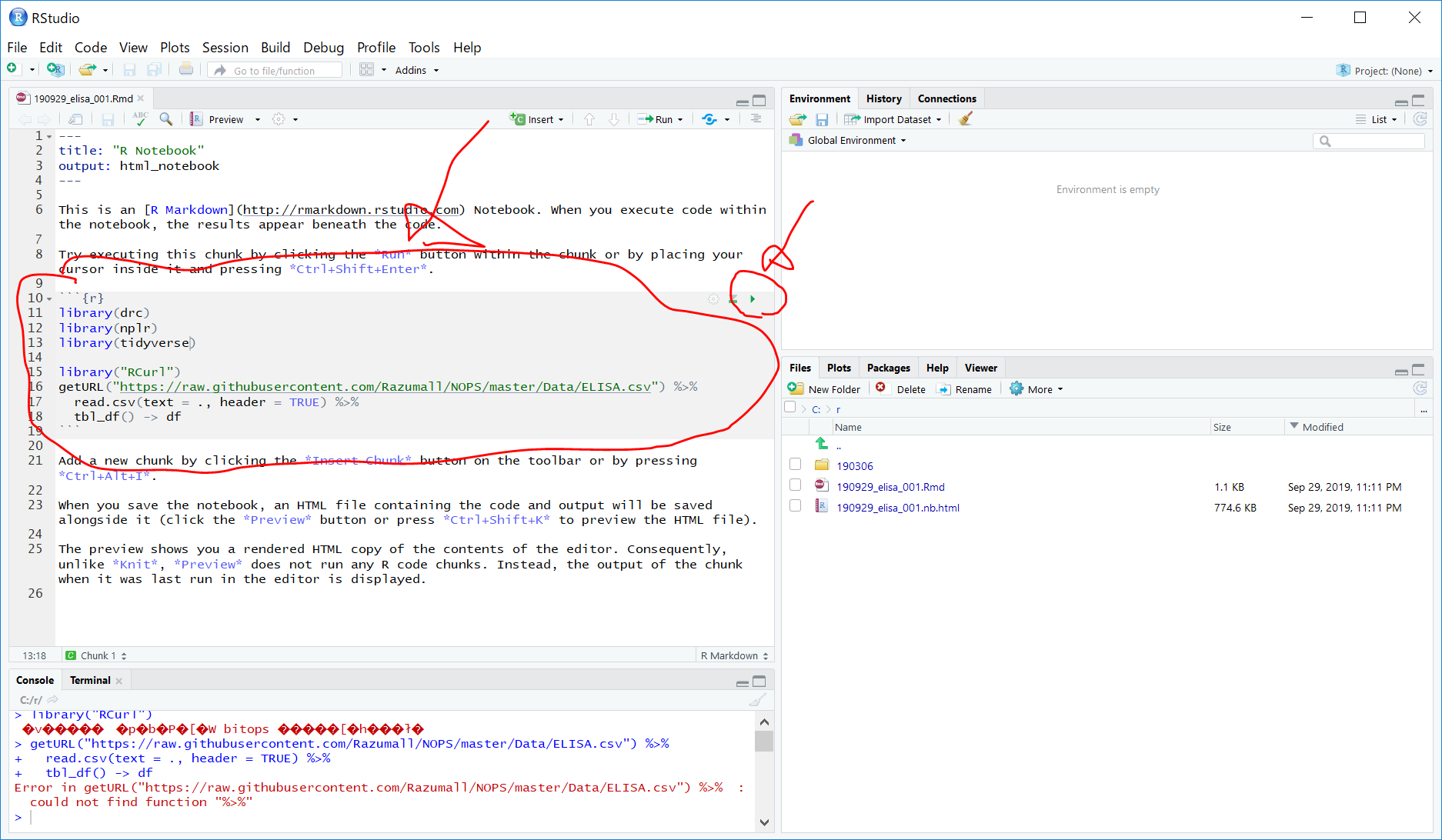
Ctrl+S で保存した後、グレーの部分の右上の▲ボタンを押すと、以下のようになります。
さらに上図のように、画面右上のEnvironmentタブの、df のすぐ左側の▲ボタンをクリックすると、以下のように、dfの中身が表示されます。
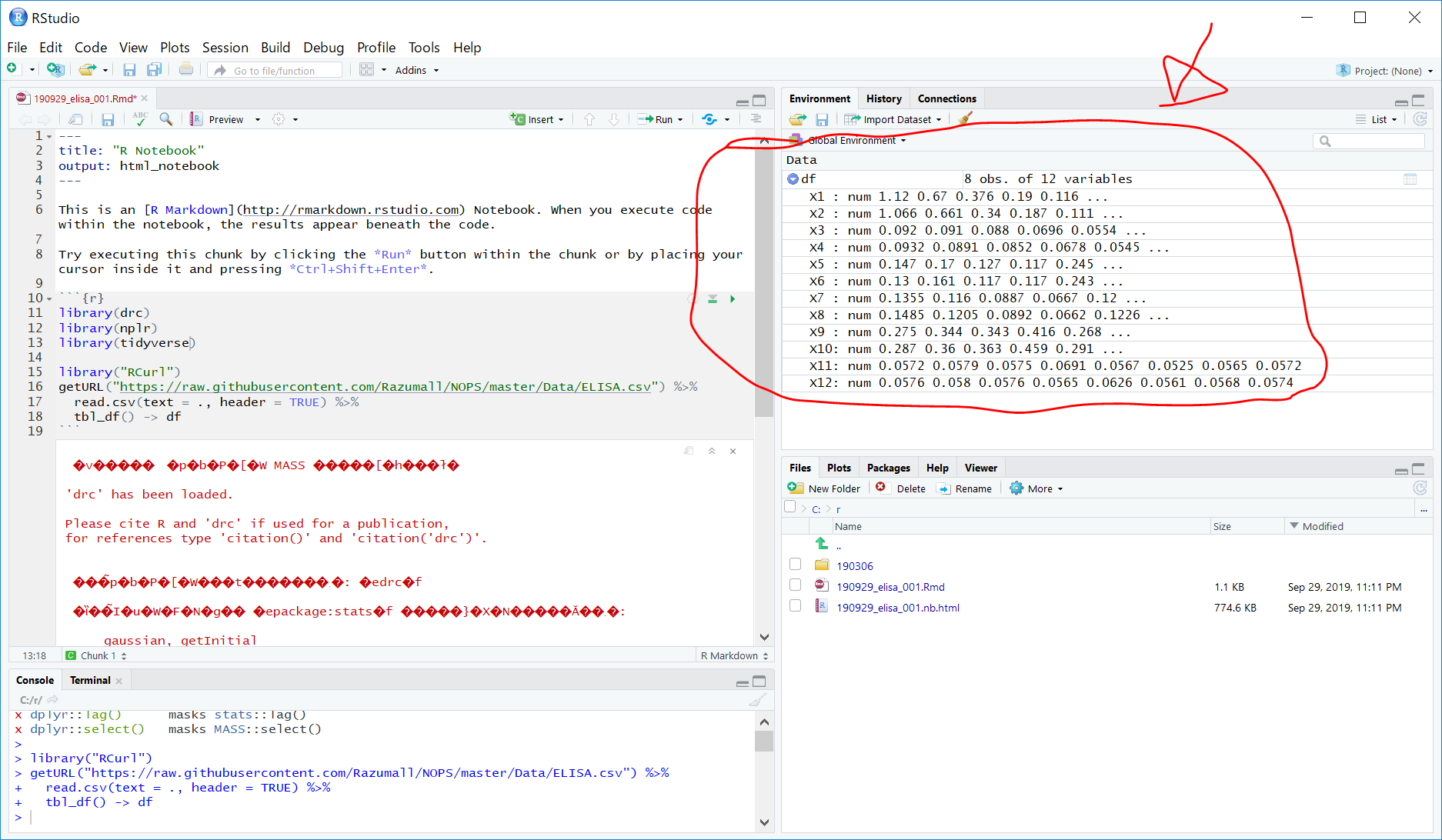
ちなみに、
https://raw.githubusercontent.com/Razumall/NOPS/master/Data/ELISA.csv
をChromeで開くと、以下のような表示になります。
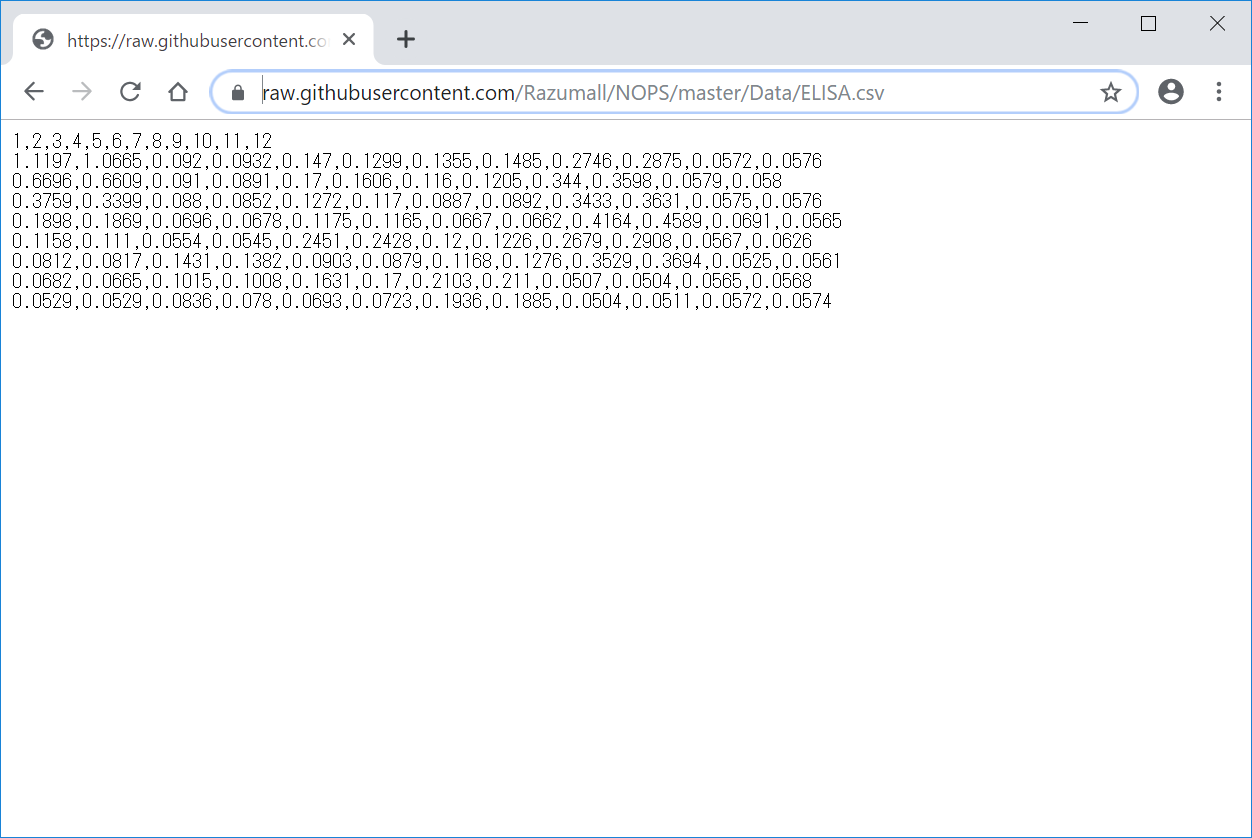
- 8行12列の96 wellプレートに、
- 吸光度の値が記載されています
- 2列ずつduplicate (同じタンパク濃度のサンプルが2つずつ横に並んでいる)になっており、
- 左の2列がstarndandになっており、
- standardは上から順に1000, 500, 250, 125, 62.5, 31.25, 15.625, 0(blank)となっており、
- 残りの右側の 5(サンプル)x 2(duplicate) = 10列が測定したいサンプルの吸光度
となっているそうです。
バックグラウンドの値を差し引く
何もいれなかった8行1列、8行2列のwellの吸光度をバックグラウンドとして、全体の値から差し引きます。
Rの式を入れたい場所(今回は20行目)を選択した状態で、”C”マークの “Insert" > R の順にクリックして、Rのコードを挿入します。
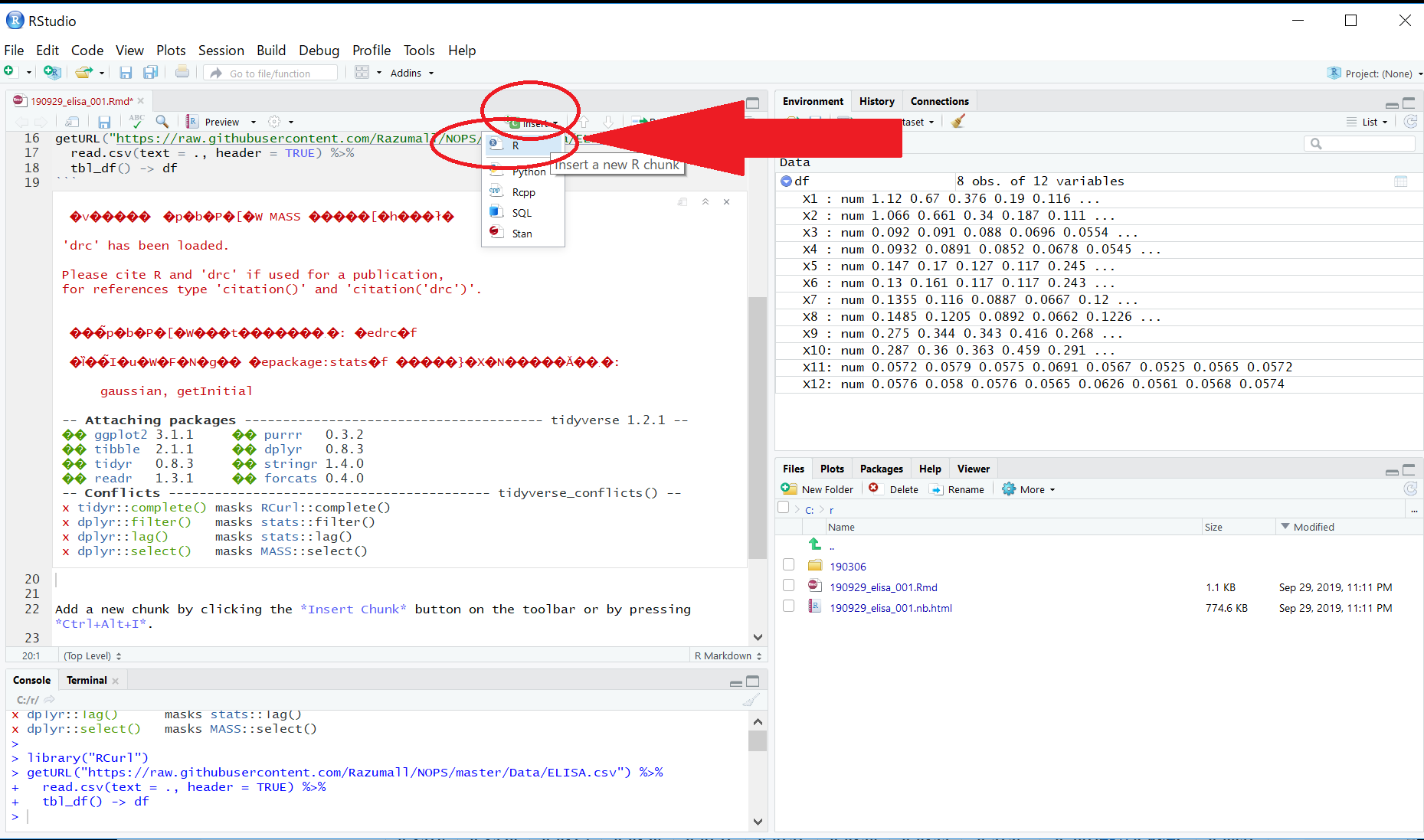
以下のコードをグレーの部分に記載して、Ctrl+Sで保存します。
df %>%
mutate_all(funs(. - as.numeric((df[8,1]+df[8,2])/2 ))) -> df2下図の▲ボタンを順にクリックしていきます。
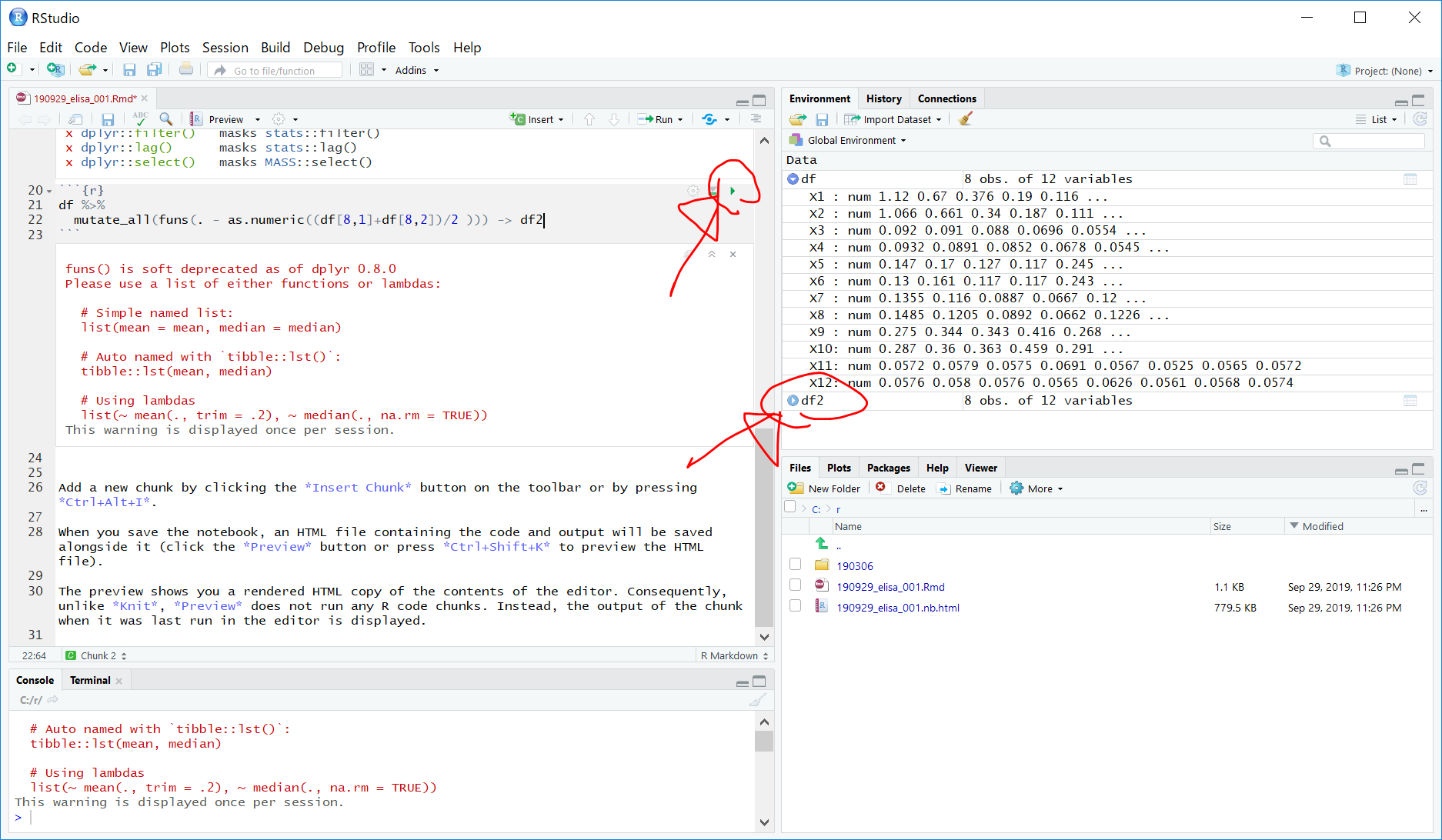
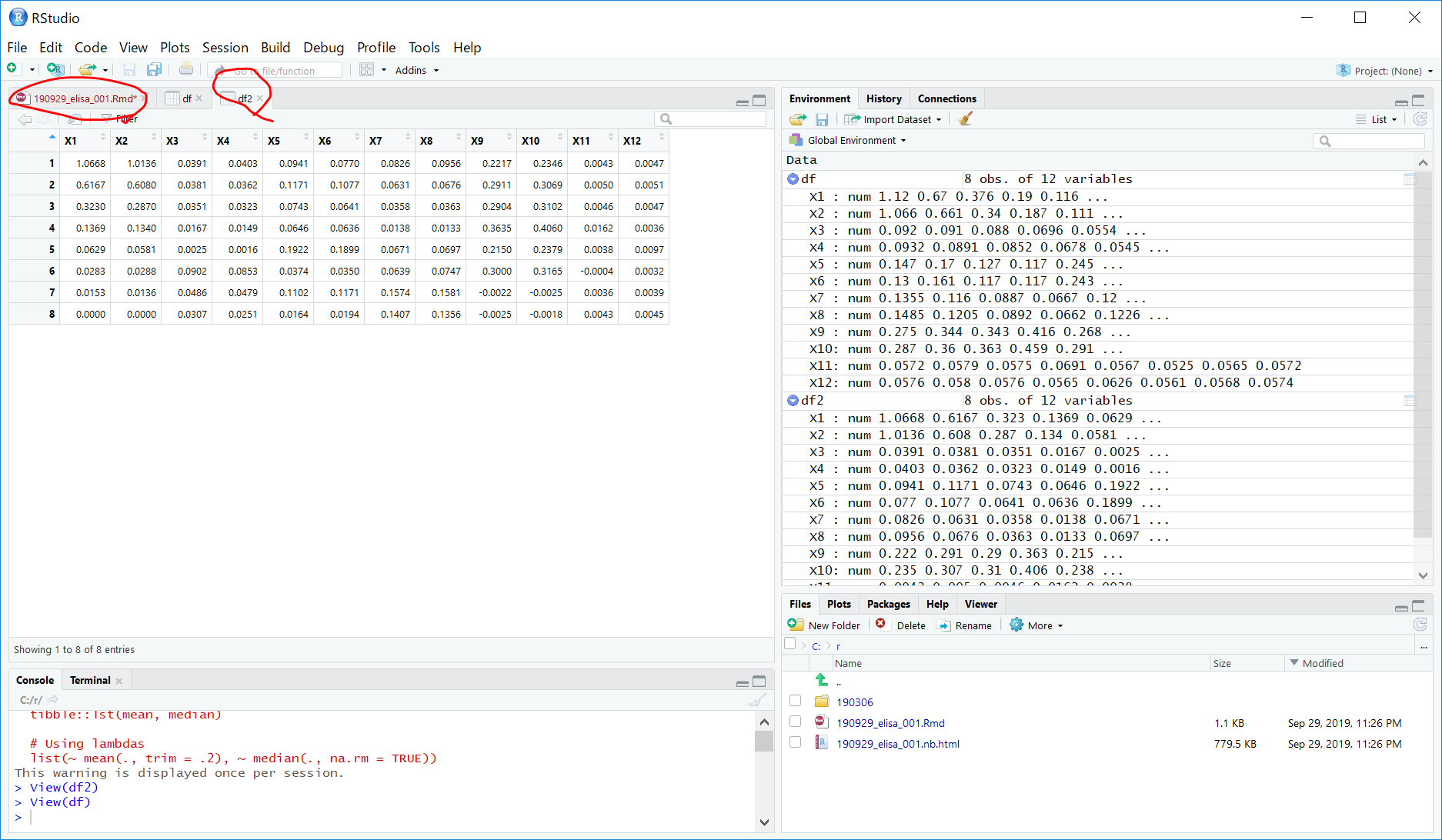
スタンダード曲線を描く
横軸がタンパク室濃度、縦軸が吸光度の散布図を描きます。
25行目を選択した状態で 、"Insert" > R の順にクリックして、以下のRのコードを挿入します。
df2 %>%
dplyr::select(X1, X2) %>%
mutate(Concentration = c(1000*0.5^(0:6), 0)) %>%
gather(Column, Absorbance, -Concentration) %>%
filter(Concentration!=0) %>% # バックグラウンドは除去する
dplyr::select(-Column) -> Standard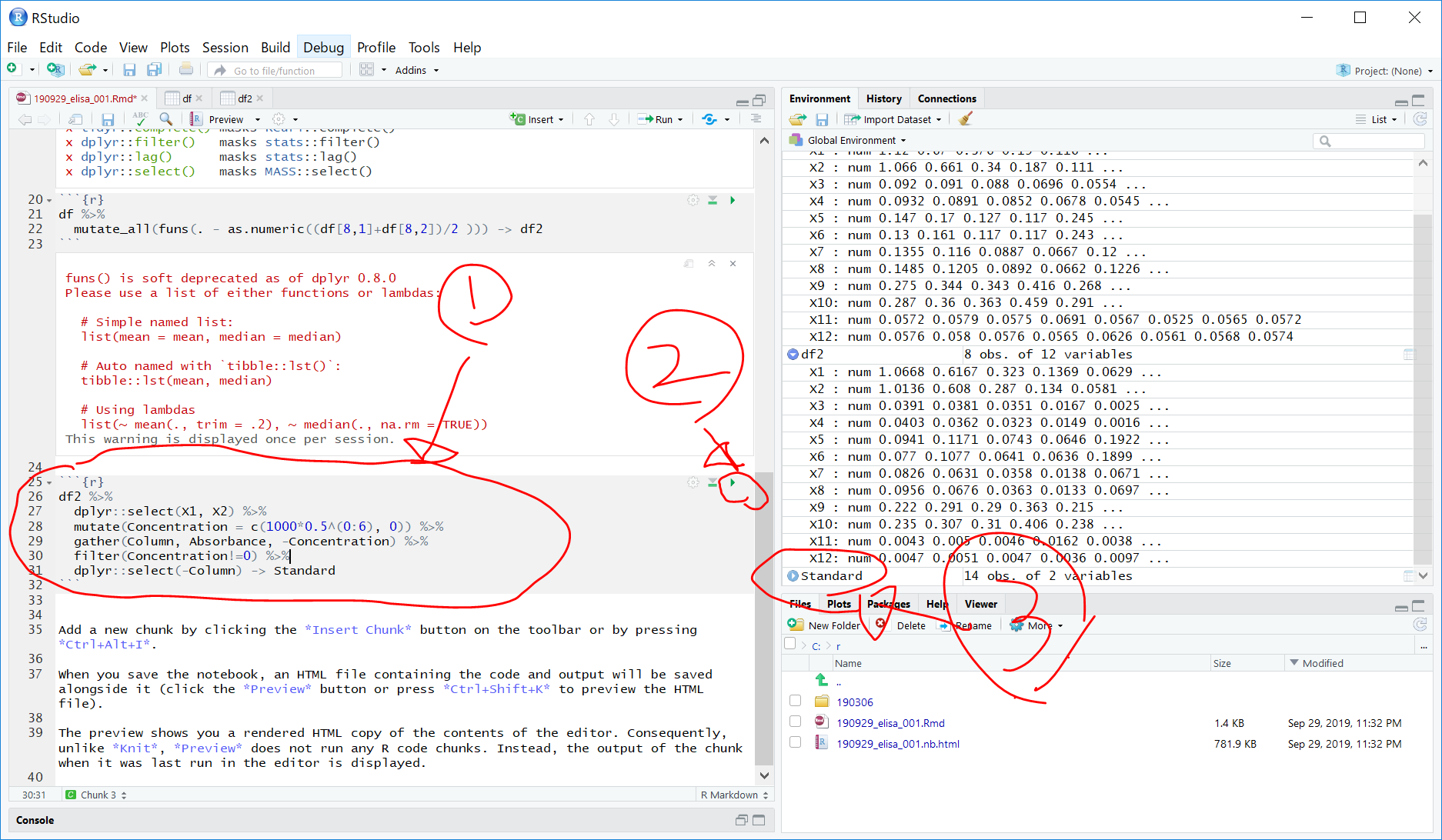
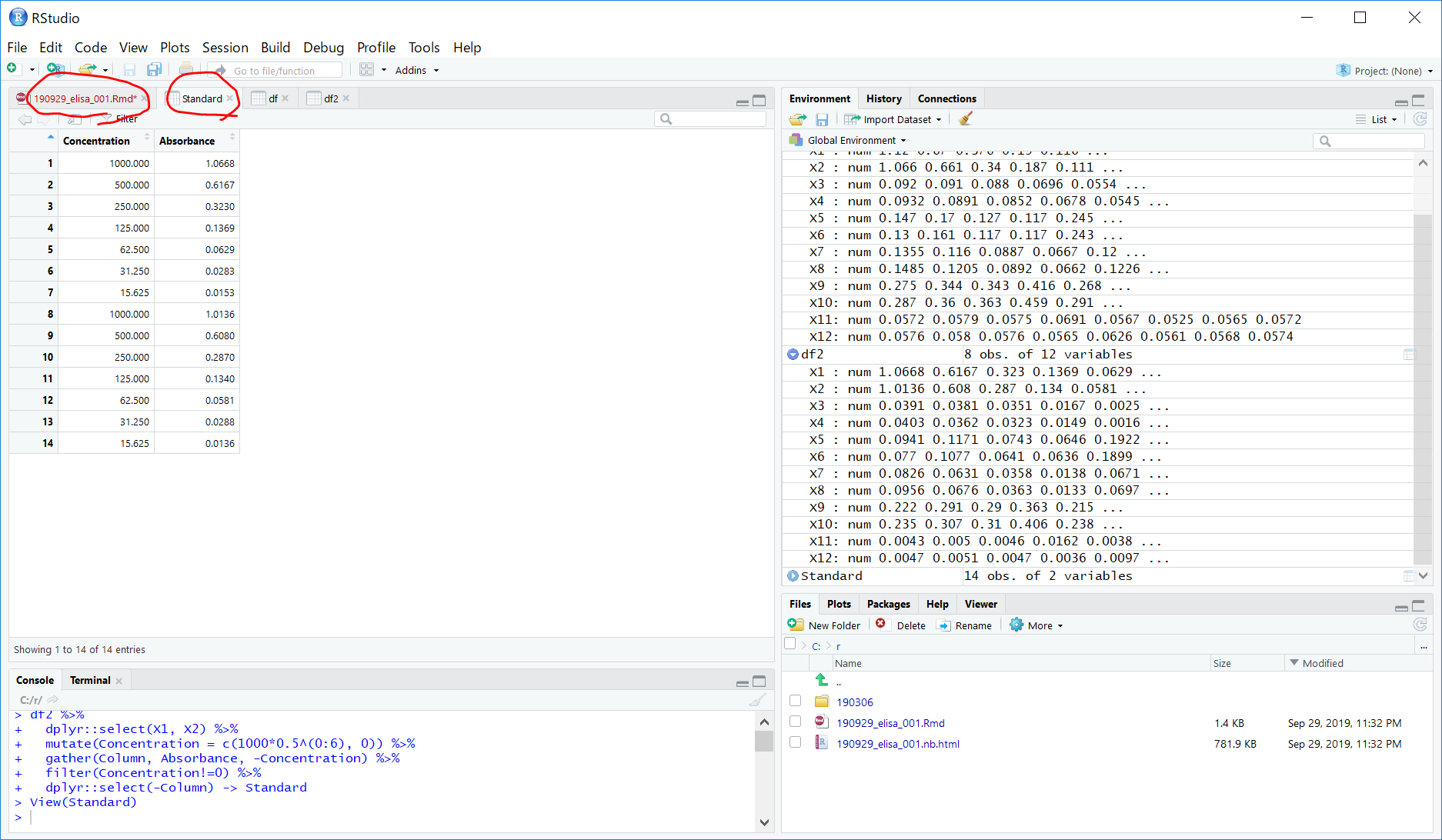
これをggplot2で散布図を描きます。
なお、x軸をlog scaleにします。
ggplot(Standard, aes(x=Concentration, y=Absorbance))+
geom_point()+
scale_x_log10()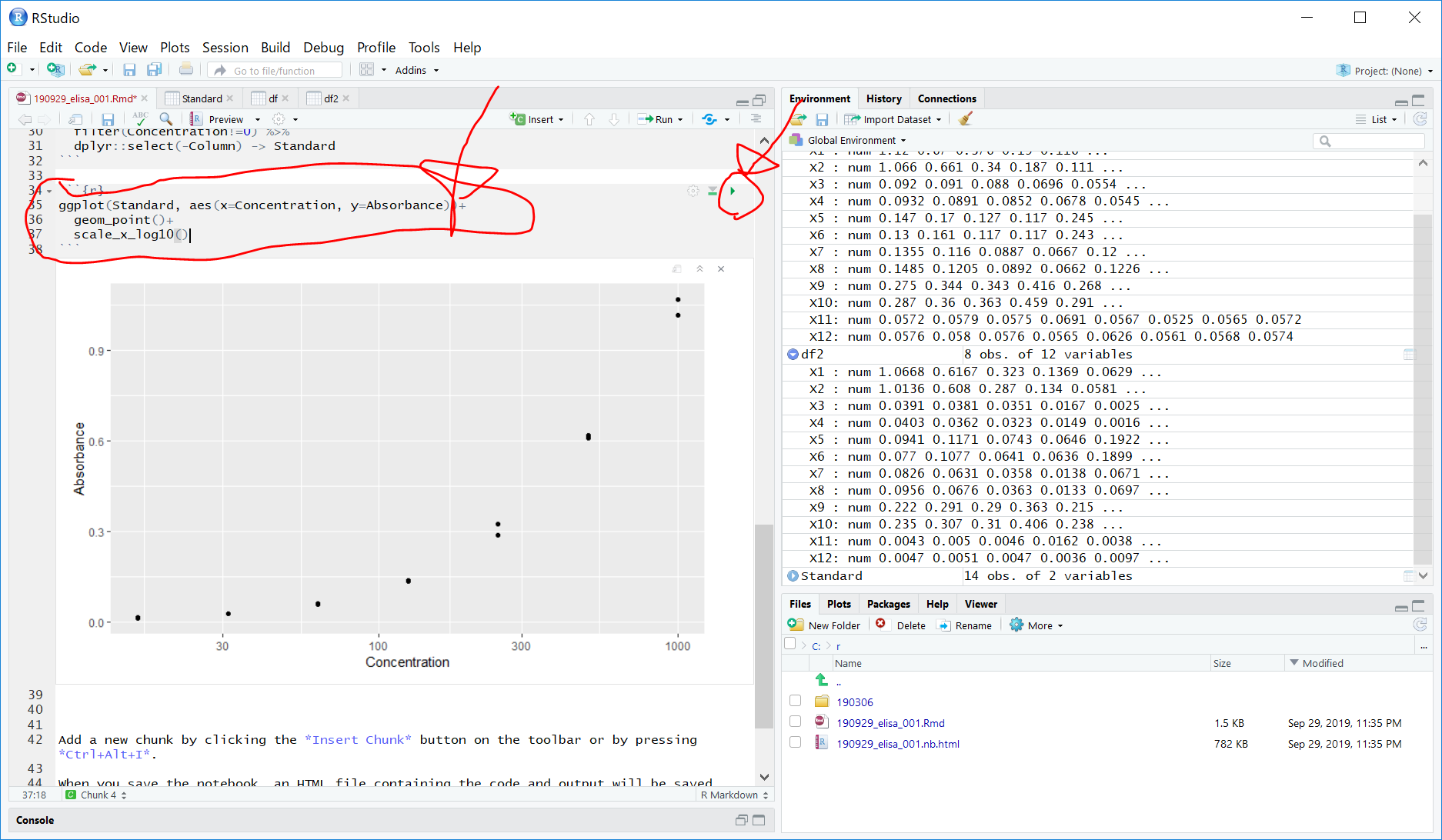
4パラメーターロジスティック回帰の回帰式を求めて
(4-P logistic model)、サンプルのタンパク質濃度を計算する
以下のコードを入力して『モデルの作成』を行います。
library(nplr)
nplr <- nplr( x = Standard$Concentration,
y = Standard$Absorbance )
nplr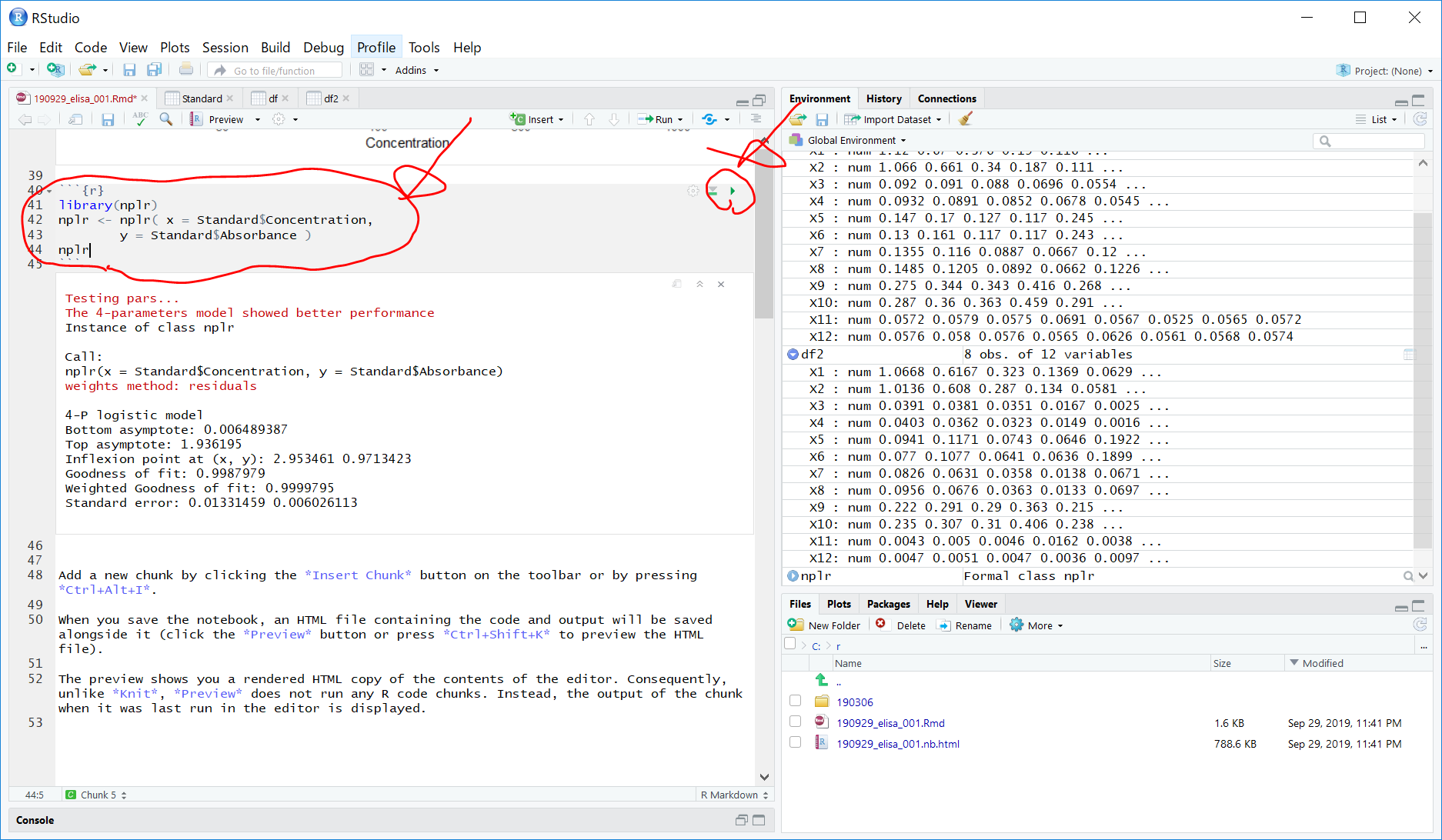
回帰曲線をプロットします。
plot( nplr,
xlab="Concenttration",
ylab="Absorbance")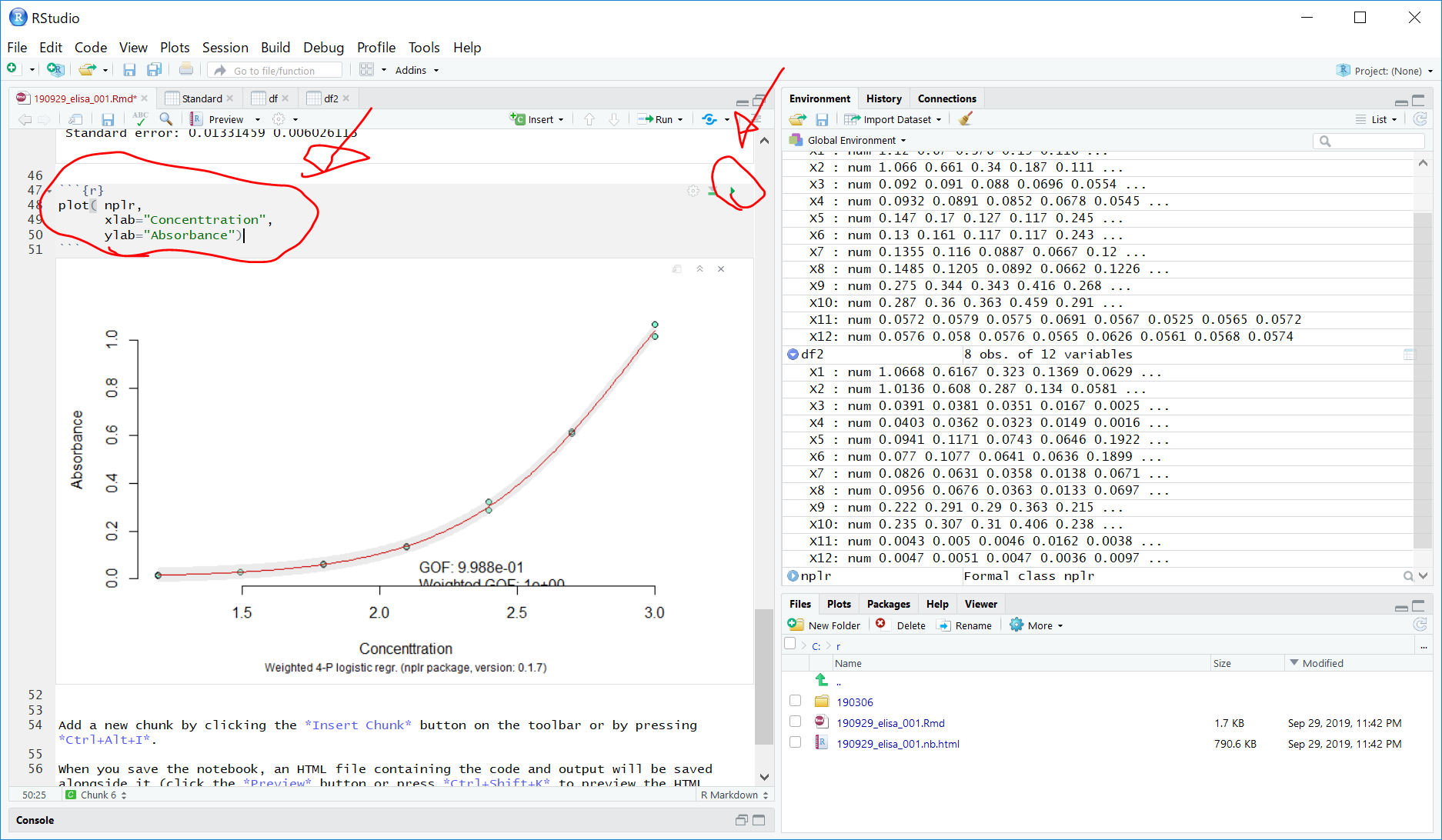
サンプルの吸光度から、タンパク質濃度を計算します
df2 %>%
dplyr::select(-c(X1, X2)) %>%
gather(Column, Absorbance) %>%
mutate(Sample = c(rep(1:8, 2), rep(9:16, 2), rep(17:24, 2), rep(25:32, 2), rep(33:40, 2)) ) %>%
mutate(Sample = as.factor(Sample)) %>%
group_by(Sample) %>%
summarise(Mean = mean(Absorbance), SD = sd(Absorbance)) -> Measured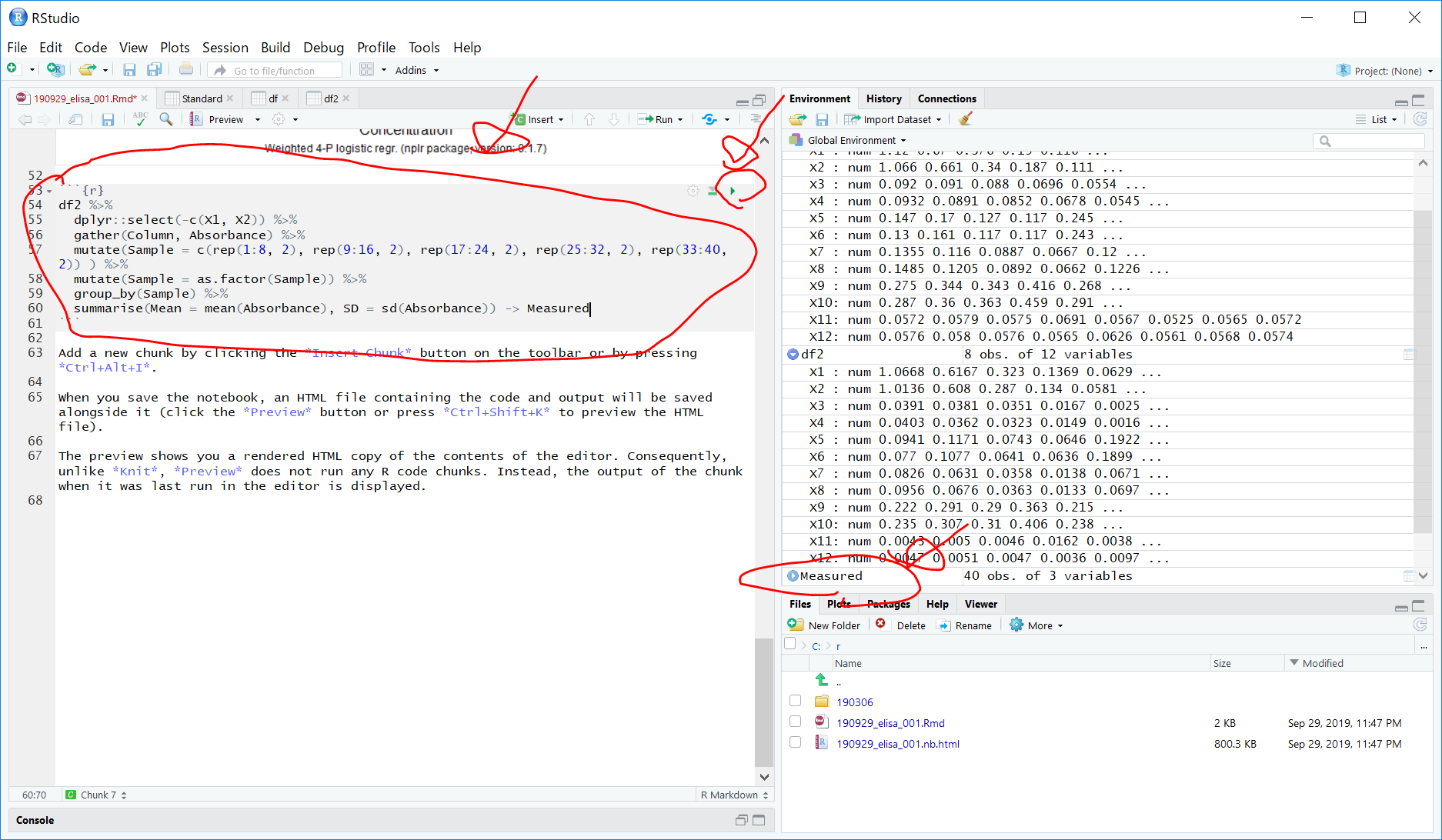
96well から、一番左2列x8(スタンダード)を除いた、80well, duplicateなので、80/2 = 40 サンプルのタンパク質濃度を求めることになります。
Mean > 0 のものだけを残して(Filterをかけて)、Concentrationを予測します。
Measured %>%
filter(Mean > 0) -> Measured2
getEstimates(nplr, Measured2$Mean) %>%
tbl_df() %>%
dplyr::rename(Absorbance=y, Concentration=x) -> Estimates_nplr
一部の値が小さすぎてestimateできませんというエラーが出てしまう。。。filterを Mean > 0 よりもある程度大きな値にするべきなのか?よくわからない。。。
しかし、一応、タンパク質の濃度はConcentrationとして計算はできたようです。。。
ソースコード
Rmdファイルは、以下となります。
あらかじめ、console画面で、3つのパッケージのインストールをしておく必要があります。
install.packages("drc", dependencies = TRUE)
install.packages("nplr")
install.packages("tidyverse")参考文献
https://www.pediatricsurgery.site/entry/2017/01/30/202953

上記サイトのコードをコピペしただけなのですが、疲れました。。。自分のデータで計算できるだろうか。。。以下の本で、dplyrについて少し勉強しないといけなさそうです。。。
以下は英語のサイトですが、結構わかりやすいです。