dplyr(tidyverse)でsummarise()関数で標準偏差sdを計算するとNAになってしまうときは平均meanの名前の付け方に注意
キーワード:tidyverse, dplyr, summarise, mean, sd, NA
Rで、平均の折れ線グラフなどを描くときの流れとして
- library(tidyverse)
- group_by()とsummarise()を用いて各グループの個数、平均、標準偏差を計算した表dを作成
- ggplot()でグラフを描画
が、個人的にお勧めです。
しかし、ちょっと気を抜くと、summarise()関数で標準偏差sdを計算しようとすると、sdだけNAになってしまうことがあります。2020年8月現在、公式ページの例が以下のような記載で困りましたが、こちらにHadley Wickhamご本人が解決法を書かれています。
mtcars %>%
group_by(cyl) %>%
summarise(disp = mean(disp), sd = sd(disp))
#> `summarise()` ungrouping output (override with `.groups` argument)
#> # A tibble: 3 x 3
#> cyl disp sd
#> <dbl> <dbl> <dbl>
#> 1 4 105. NA
#> 2 6 183. NA
#> 3 8 353. NAContents
ソースコード
https://colab.research.google.com/drive/1yPHODB6sgUU9OJx48tEibAF9rnUHDv-s?usp=sharing
『解決法1』summarise(mean_len=mean(len), sd_len=sd(len))のように書く
len=mean(len) と書くと、lenがベクトルではなく1個の値になってしまい、次の行でsdを計算してくれなくなってしまいます。 →ソースコード
library(tidyverse)
head(ToothGrowth)
str(ToothGrowth)
d <- ToothGrowth %>%
group_by(supp, dose) %>%
summarise(
n=n(),
mean_len=mean(len),
sd_len=sd(len)
)
# 蛇足だが、以下の書き方はsdがNAになってしまう
# https://dplyr.tidyverse.org/reference/summarise.html
# summarise(n=n(), len=mean(len), sd=sd(len))
d
pd <- position_dodge(0.1) # move them .05 to the left and right
ggplot(d, aes(x=dose, y=mean_len, shape=supp)) +
theme_set(theme_classic()) +
geom_point(size=4, position=pd) +
geom_errorbar(aes(ymin=mean_len-sd_len, ymax=mean_len+sd_len), width=.1, position=pd) +
geom_line(aes(linetype = supp), position=pd) +
# グラフにタイトルをつける
ggtitle("ToothGrowth") +
theme(plot.title = element_text(hjust=0.5)) +
theme(plot.title = element_text(size = 20),
axis.title.x = element_text(size= 20),
axis.title.y = element_text(size= 20),
axis.text.x = element_text(size= 20),
axis.text.y = element_text(size= 20)
) +
# y軸のラベルの書き換え
labs(y="Length")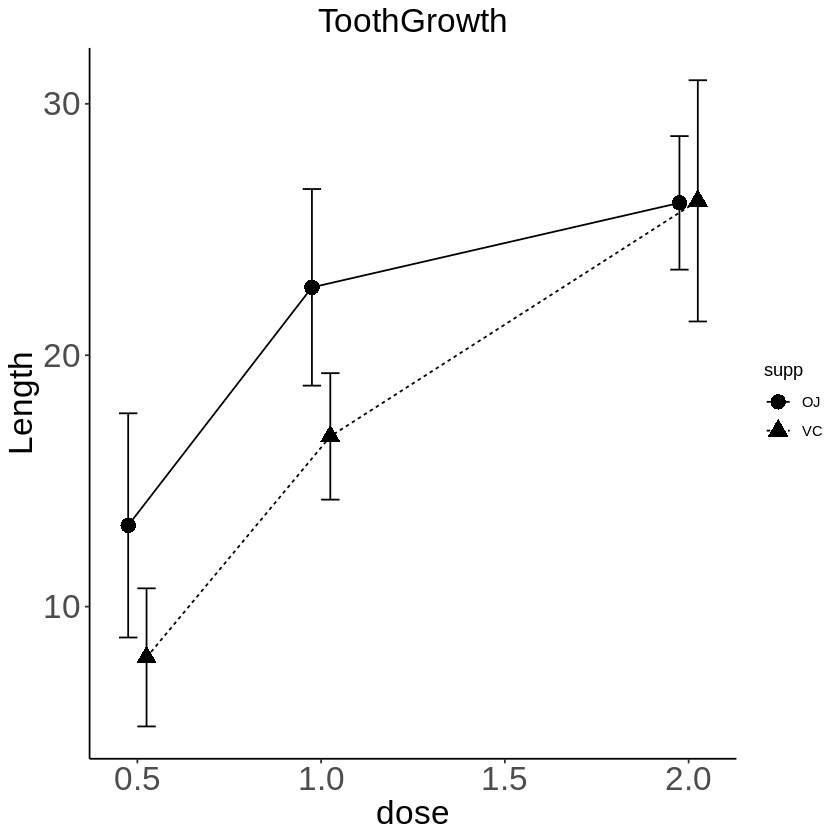
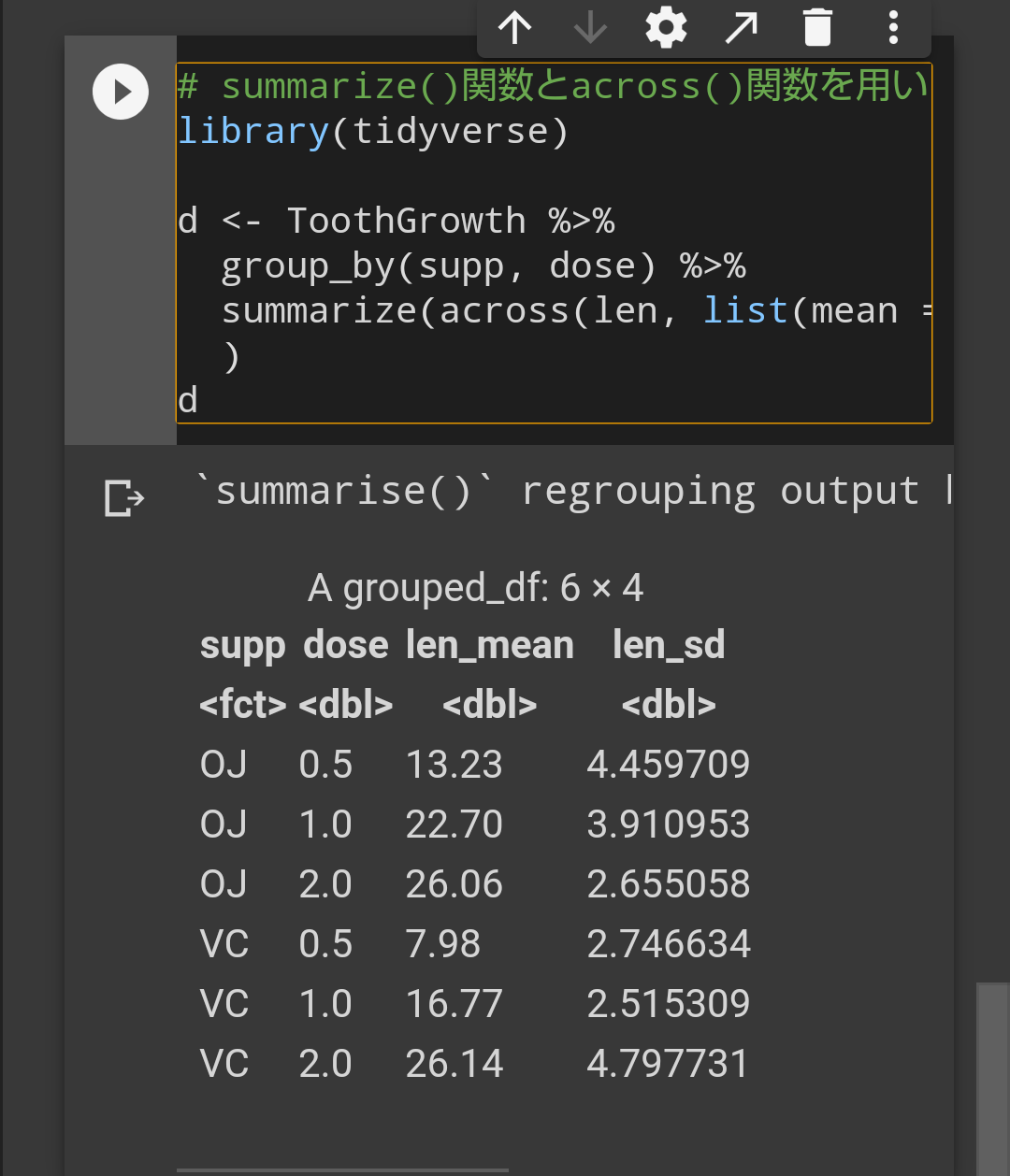
『解決法2』summarise()関数とacross()関数を用いる()
2020年現在、summarise_each()関数はdeprecatedとのことです。(gatherじゃなくてpivot_longerなど、いろいろ時代は変わるようです。)
少し難しそうですか、こちらの方がすっきりコードをかくことができそうです。
参考:https://dplyr.tidyverse.org/reference/across.html
summarize()関数とacross()関数を用いる方法
library(tidyverse)
d <- ToothGrowth %>%
group_by(supp, dose) %>%
summarize(
across(
len,
list(
mean = mean,
sd = sd
)
)
)
d