EZRで「線形混合モデル」(『EZRでやさしく学ぶ統計学 改訂3版 』を写経してみる)
時系列データの解析のために、「線形混合モデル」というものを用いることがあります。
EZRで「線形混合モデル」の解析をするために、『EZRでやさしく学ぶ統計学 改訂3版 〜EBMの実践から臨床研究まで〜 単行本(ソフトカバー) – 2020/11/16』を購入しました。

そもそも『線形混合モデル』がいったい何のかさっぱりわからないため、とりあえず、そのまま、写経してみたいと思います。
開発環境
Windows10 Pro (1909)
EZR 1.50 (June 4, 2020)WindowsへのEZRのインストールは、https://www.jichi.ac.jp/saitama-sct/SaitamaHP.files/download.html からインストーラーをダウンロードしてダブルクリックして進めるのみです。
必要なもの
全く同じデータを用いる場合は、 『EZRでやさしく学ぶ統計学 改訂3版』 のDVD-ROMが必要です。電子書籍がなく、紙の書籍のみで、約5000円もしますが、Rの説明もあり、ぜひおすすめです。
似たようなデータは自分で作ることもできますし、こちらのサイト(の、data_long.xlsx)からもダウンロードできます。
線型混合モデルとは
参考:https://ameblo.jp/forever-being-with-you/entry-12128449844.html 混合効果モデルについて 2016年02月13日
- 特に経時的研究においてある項目を繰り返し観察する反復測定デザイン等で有用である
- 欠測値の取り扱いに優れている
- Rではlme4パッケージ、lmerTestパッケージを使って混合モデルで分析
例えば、糖尿病患者のHbA1cの値を薬投与開始前、1か月後、2か月後、3か月後に測定するような場合などは、
- repeated measures ANOVA
を用いることができます。がしかし、欠損値があったりした場合などは、
- 線形混合モデル
を用いる方がよさそうであり、今後はこちらが経時的研究の解析の主流な解析法になると思われます。2016年の時点ではEZRに『線形混合モデル』は無かったのですが、2021年現時点では、
統計解析 > 連続変数の解析 > 線形混合モデル
で、解析することができます。
対応のある3群以上の平均値の比較、反復測定の分散分析
まずは、repeated measures ANOVAを写経してみます。
『EZRでやさしく学ぶ統計学 改訂3版』 p209
(1) repeated measures ANOVA
対応のある3群以上の平均値の比較、反復測定の分散分析
rdaファイルの読み込み
ファイル > 既存のデータセットを読み込む > FCZ_CSA.rda を選択して 開く
表示 でデータを確認。
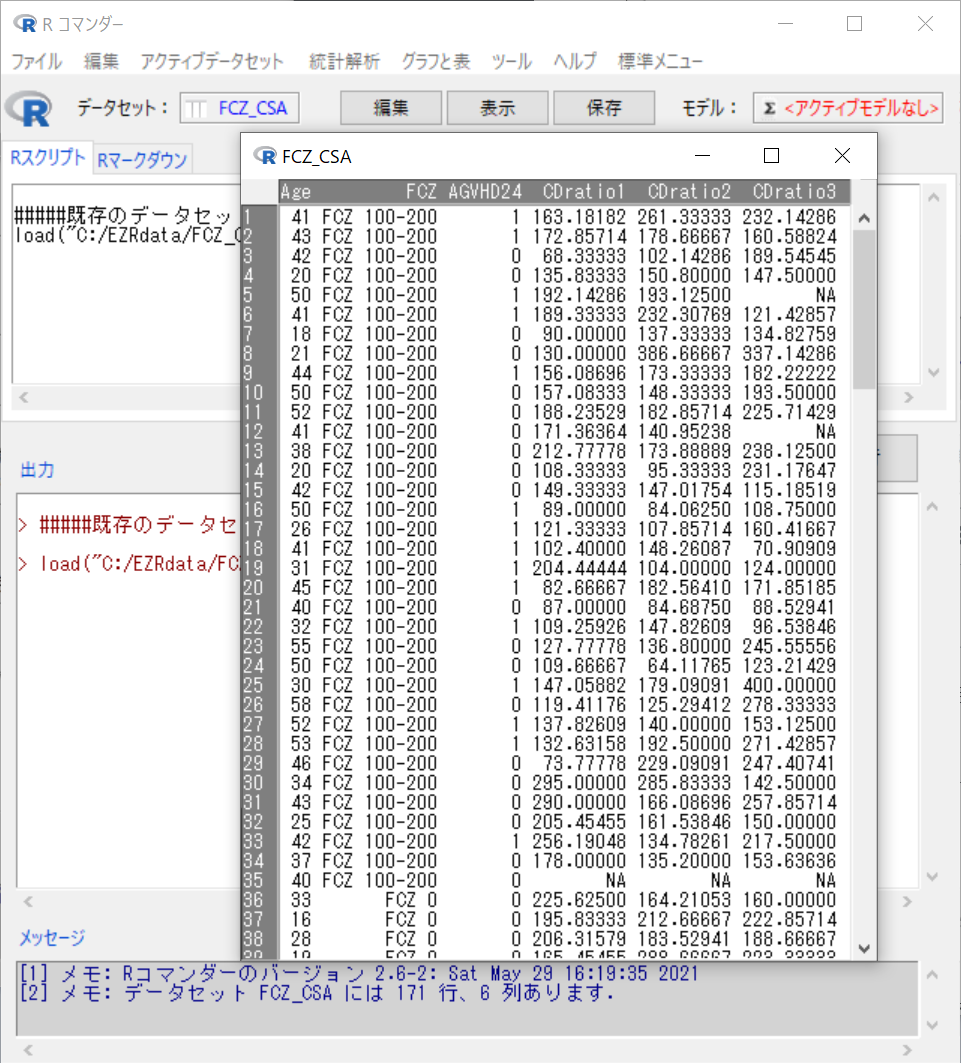
FCZ_CSA.rda
各症例の反復測定結果が1行にまとめられている = wide format = not tidy format
統計解析 > 連続変数の解析 > 対応のある3群以上の間の平均値の比較(反復[経時]測定分散分析)
2群?以上 ミスプリ?(EZR Version 1.50)
反復測定したデータをCtrlキーを押しながら複数選択 CDratio1, CDratio2, CDratio3
群別する変数 FCZ(フルコナゾール(抗真菌薬)投与量)
異なる線の区別 線種
を選択して OK
(結果)
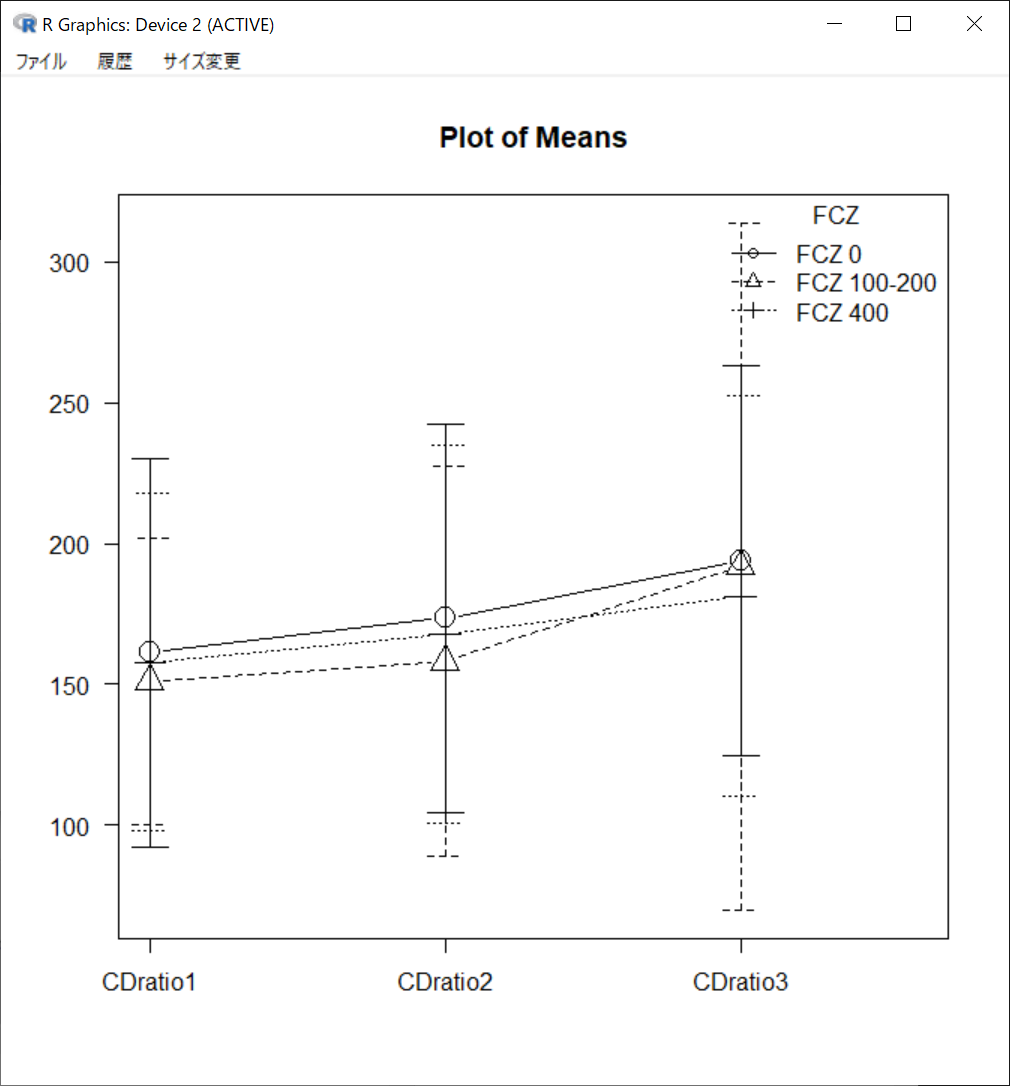
グラフ
縦軸 CDratio(血中CSA/(体重当たりのCSA投与量))
横軸 時間 CDratio1(移植1w後のCDratio), CDratio2(移植2w後のCDratio), CDratio3(移植3w後のCDratio)
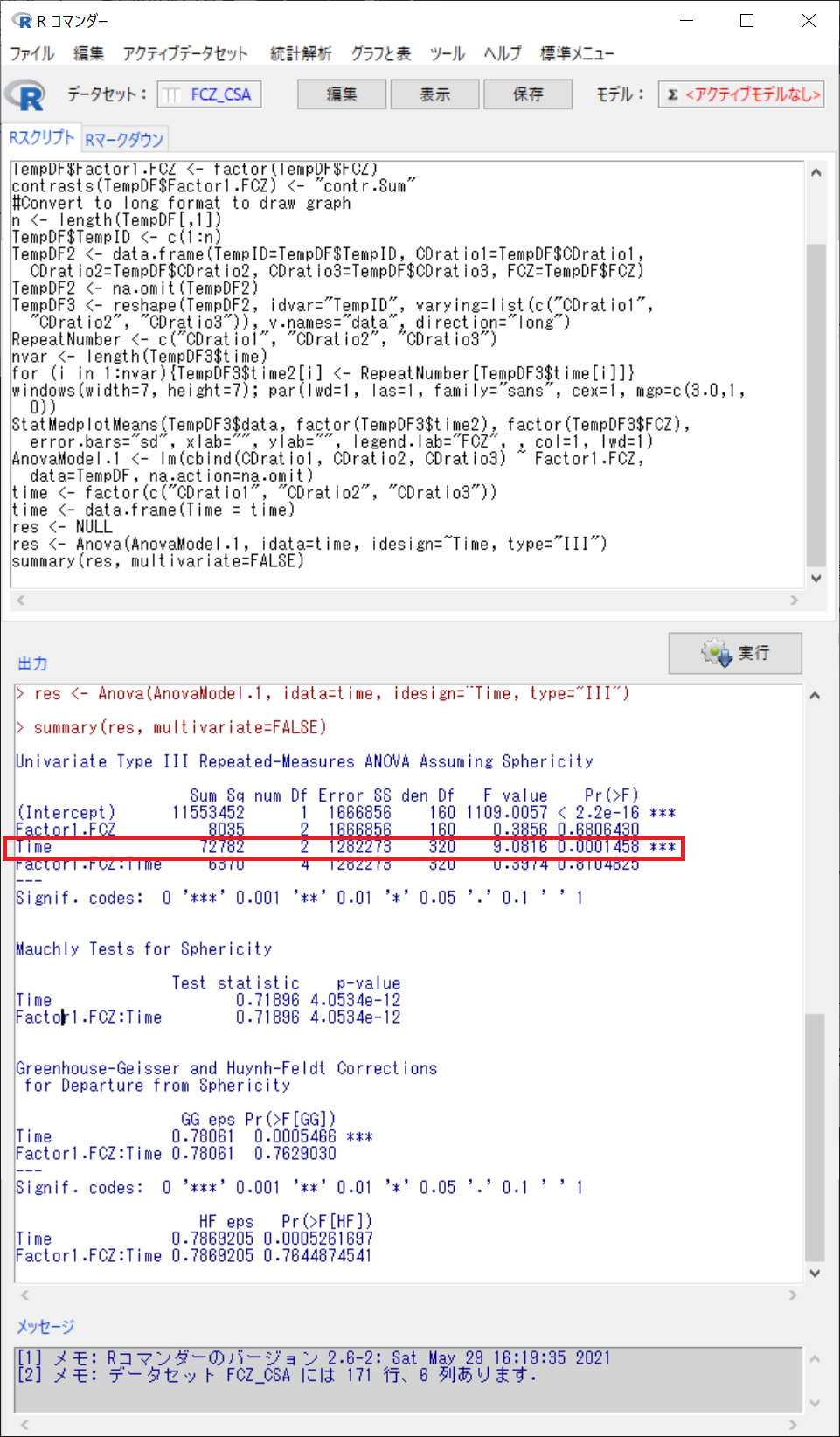
Univariate Type III Repeated-Measures ANOVA Assuming Sphericity
Factor1.FCZ p=0.68 => FCZ投与量の群間(被験者間用意)の差は有意ではない
Time p=0.0001 => C/D比は測定時期によって(被検者内要因によって)有意に異なる
Factor1.FCZ:Time p=0.81 => FCZ投与量の群間と、測定時期の間に交互作用はない
反復(経時)測定されたデータの平均値の比較、線形混合モデル(linear mixed model)
上記との同じことを、『線形混合モデル(linear mixed model) 』でやってみます。
『EZRでやさしく学ぶ統計学 改訂3版』 p246
反復(経時)測定されたデータの平均値の比較、線形混合モデル(linear mixed model)
EZRで用いるのは、lem4パッケージのlmer()関数
lmer()関数は、縦長のフォーマット long format (= tidy data) を用いる必要がある。
- wide format : 1人のデータが横長に並んだデータ
- long format : 各個人のデータが測定時期ごとに縦に並んだデータ (= tidy data )
wide format から long formatへの変換は、Rでは、tidyverseパッケージのpivot_longer()関数(参考:【tidyr】gather?, spread? もう古い。時代はpivot)を用いて行いますが、EZR上では、以下のようにマウス操作で行うことができます。
アクティブデータセット > 変数の操作 > 複数の変数を縦に積み重ねたデータセットを作成する
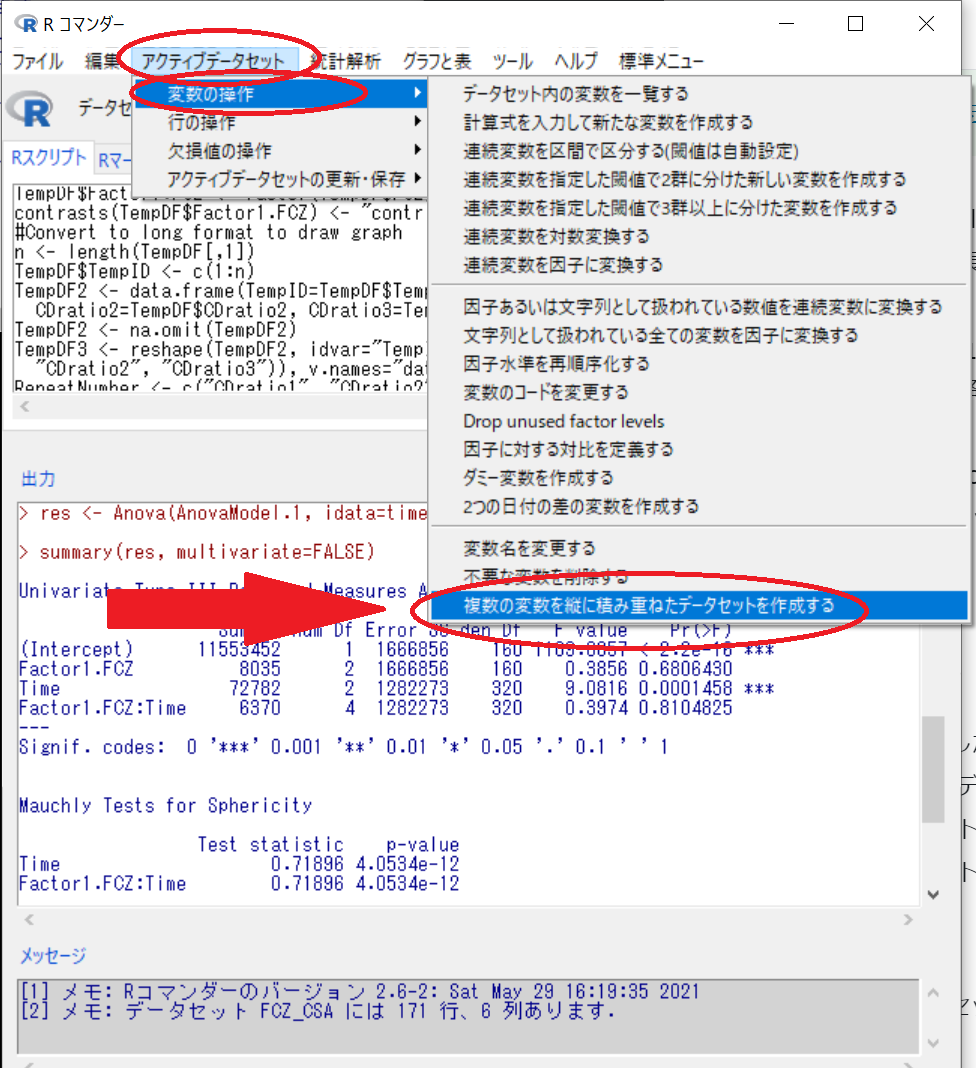
変数で、反復測定したデータをCtrlキーを押しながら複数選択 CDratio1, CDratio2, CDratio3
積み重ねて作ったデータセットの名前: FCZ_CSA_LMM
新しいデータセットでの積み重ねたデータの変数名: CDratio
新しいデータセットでの積み重ねたデータを識別するための変数の名前: Weeks
でOK
[4] メモ: データセット FCZ_CSA_LMM には 513 行、6 列あります.
表示 で確認
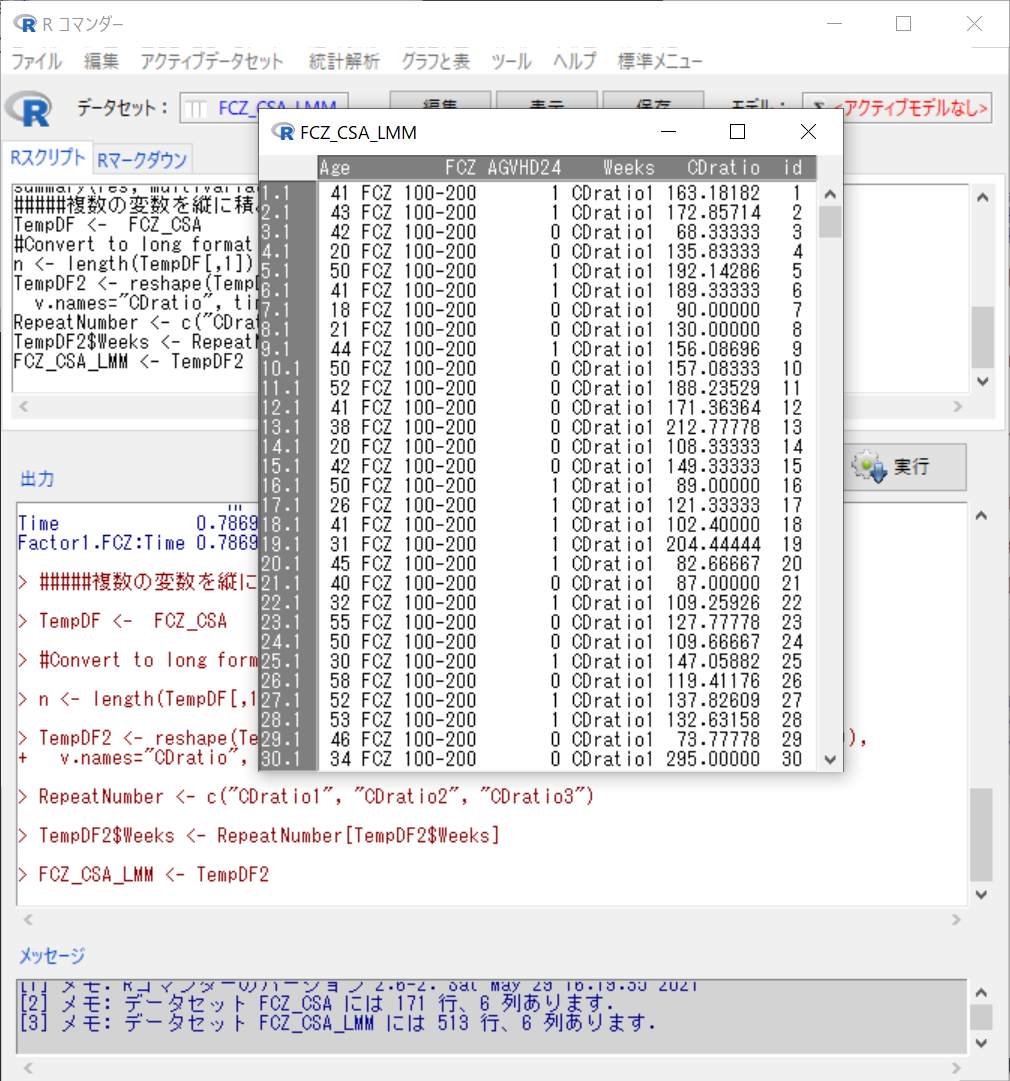
この時点では、測定時期は"CDratio1″, “CDratio2", “CDratio3″という文字列となっているので、
これを数値の文字に変換し、
さらに、(文字列から、)連続変数に変換する
アクティブデータセット > 変数の操作 > 変数のコードを変更する
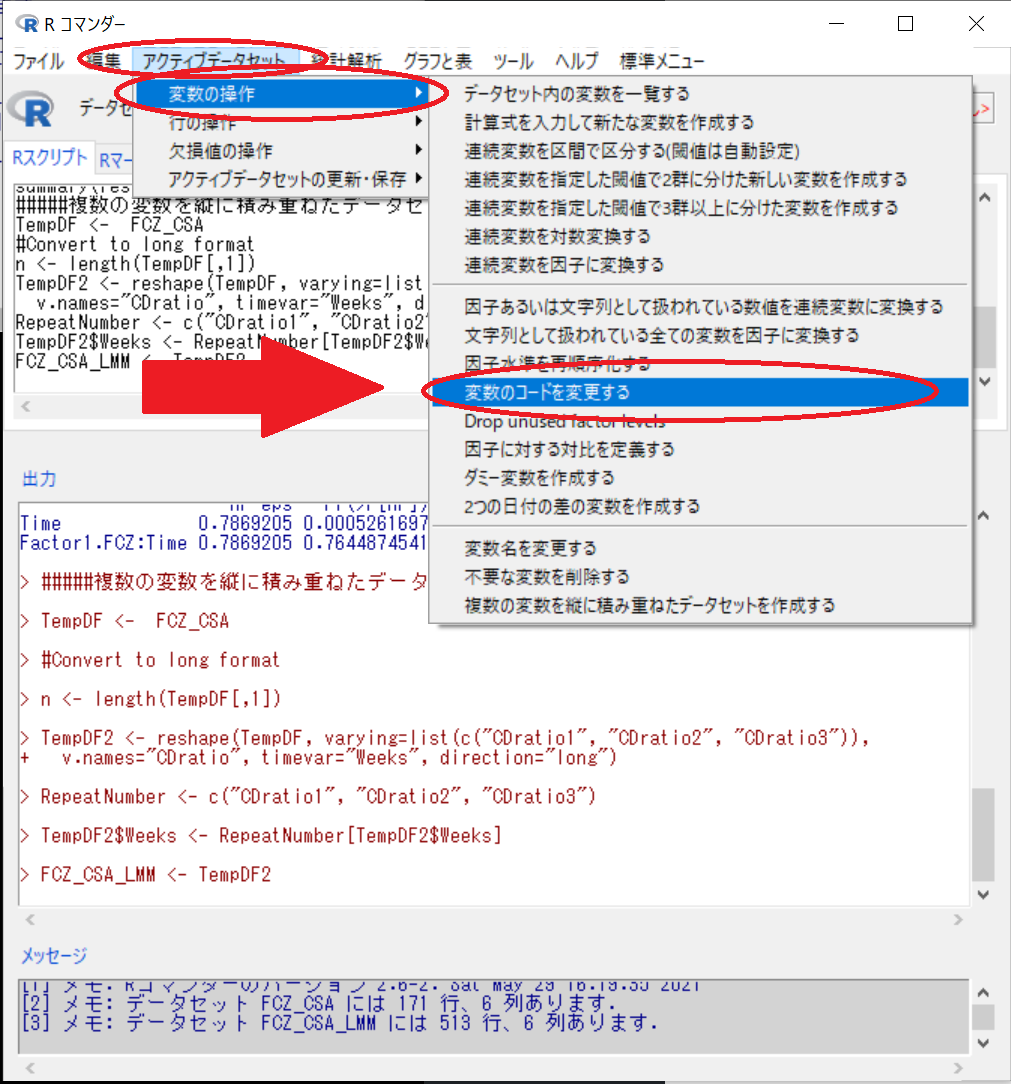
Weeks を選択
新しい変数名または複数の再コード化に対する接頭文字列: WeeksNum
“CDratio1" = 1
“CDratio2" = 2
“CDratio3" = 3
で、OK
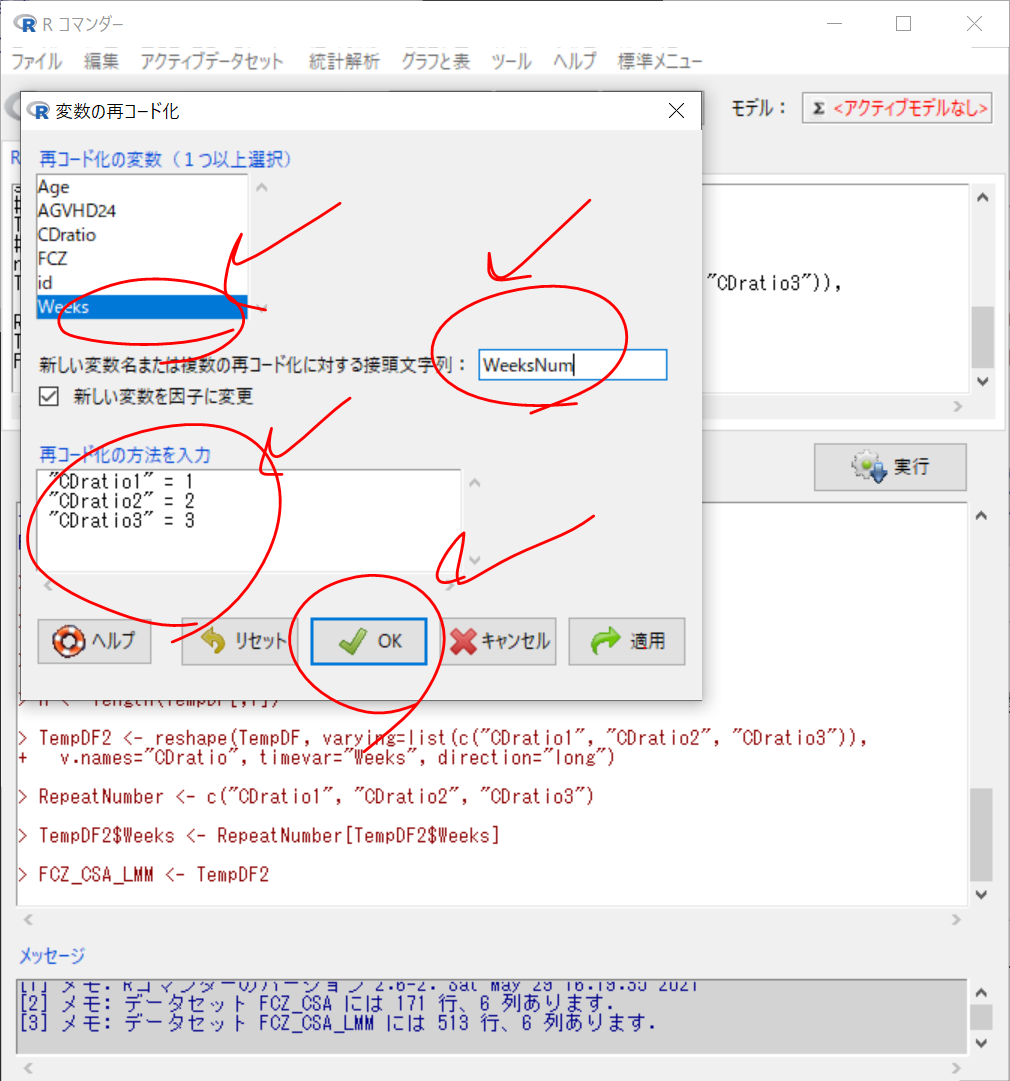
さらに、アクティブデータセット > 変数の操作 > 因子あるいは文字列と扱われている数値を連続変数に変換する
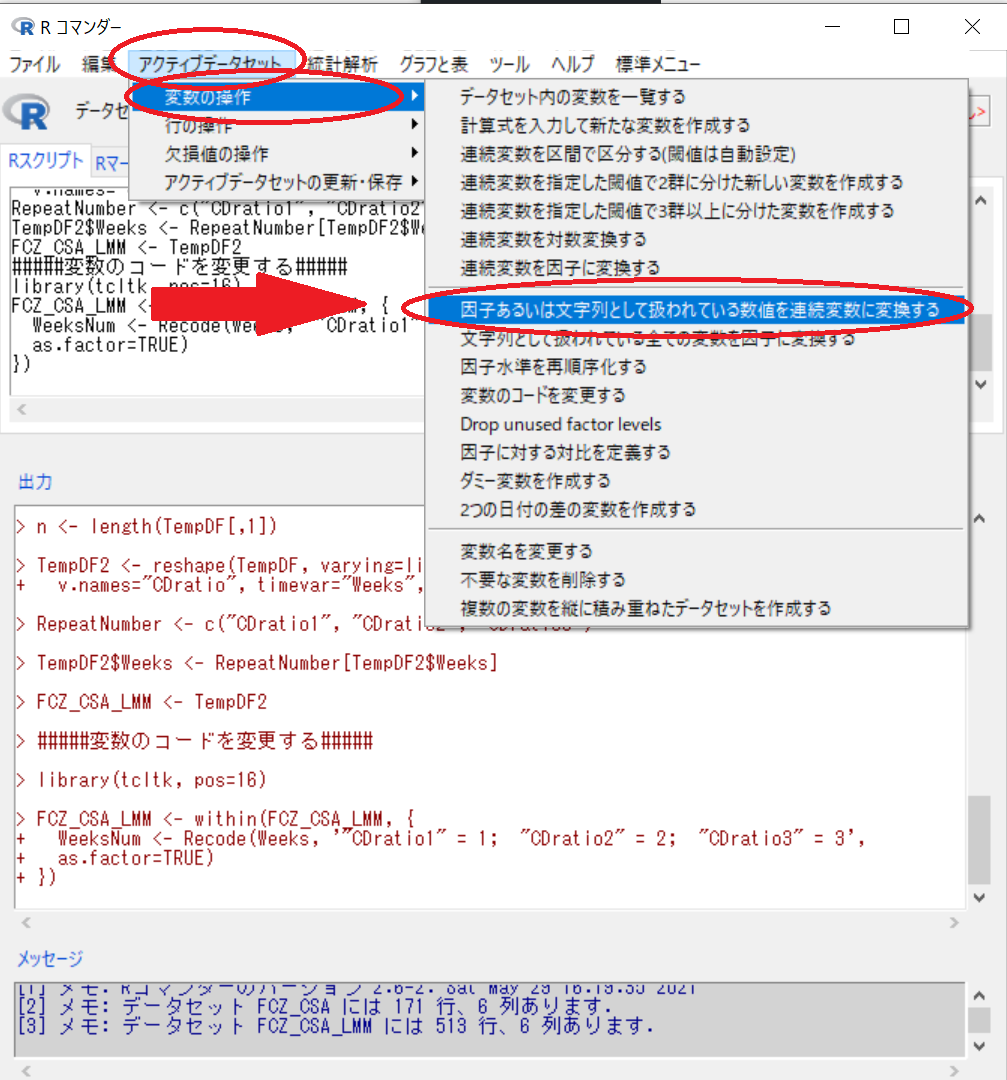
WeeksNum を選択して、OK
「変数WeeksNumがすでに存在します。変数に上書きしますか?」 → Yes
これで、WeeksNumの型が連続変数となった。
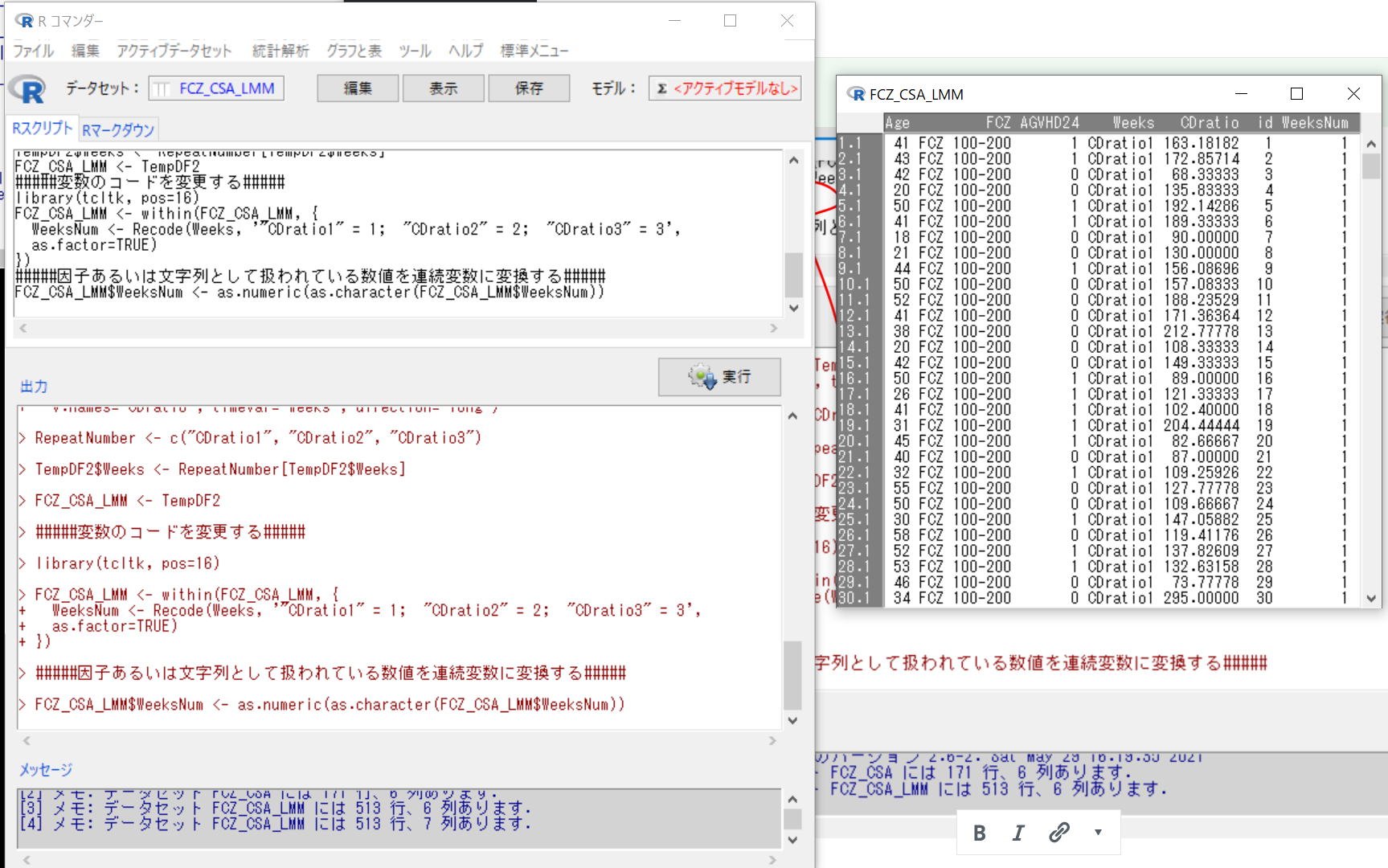
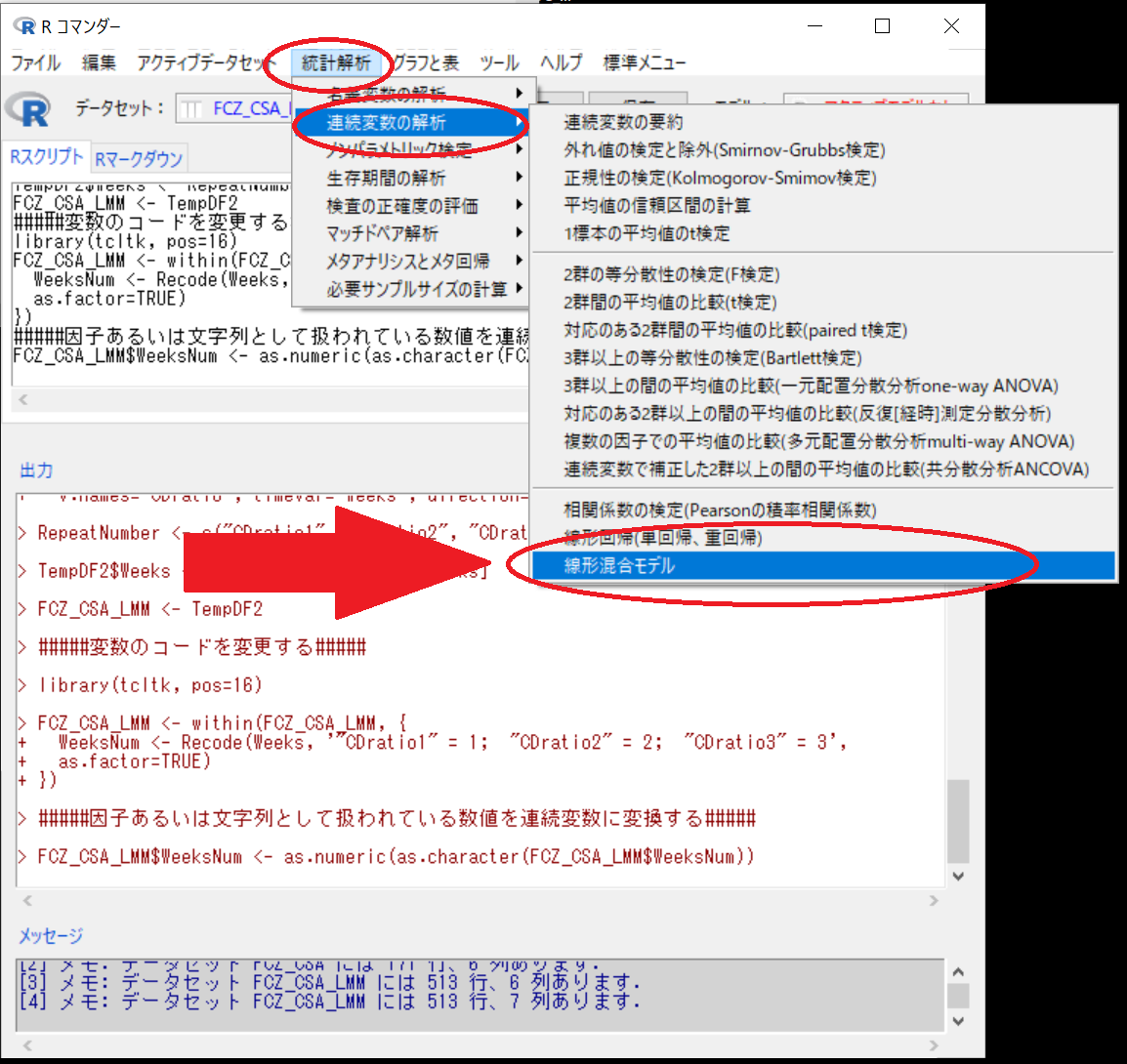
次に、線形混合モデルを実施する
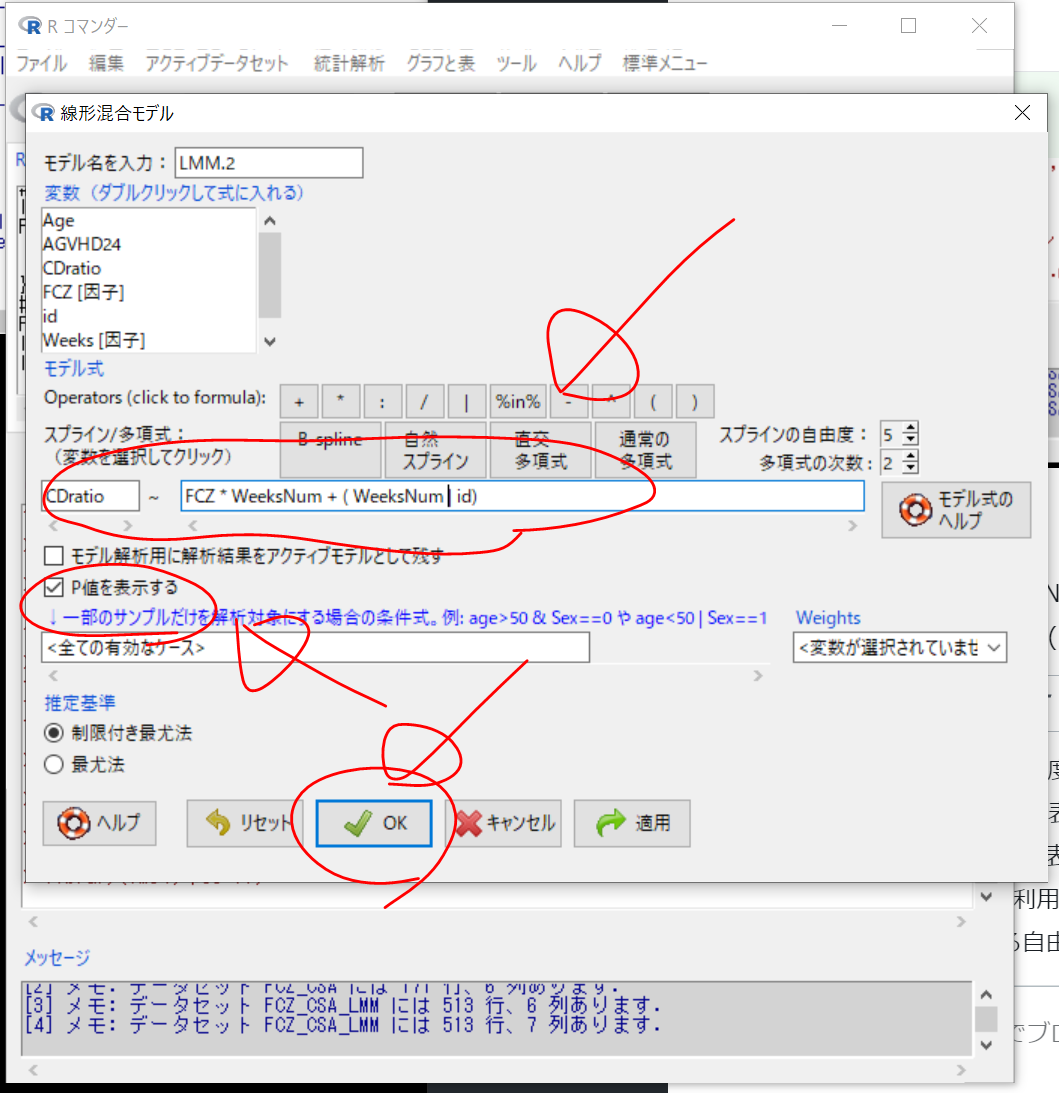
統計解析 > 連続変数の解析 > 線形混合モデル
今回は、
CDratio ~ FCZ * WeeksNum + ( WeeksNum | id)
(C/D比:血中CSA濃度) ~ (フルコナゾール投与量) * (移植後週数) + ( (移植後週数) | (患者個人))
混合モデルでは分母の自由度を定めることが難しいため、
lmer()関数は本来はP値を表示しない。
しかし、EZRでは、P値を表示するオプションを指定した場合には、
lmerTestパッケージを利用して、
Satterthwaite法による自由度に基づくP値を表示する。
(結果)
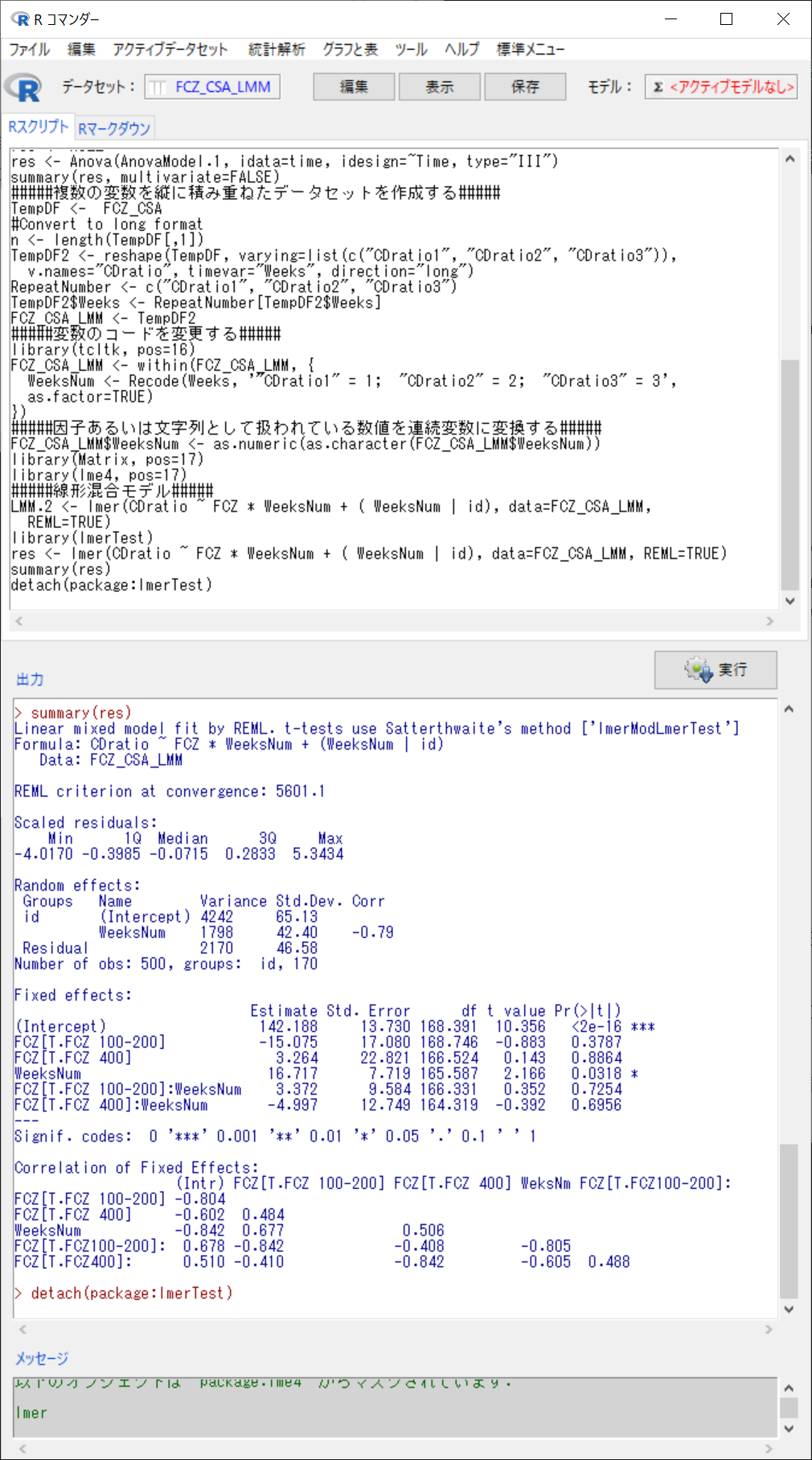
Fixes effects: のところで、WeeksNumのみが、Pr=0.0318 で、有意差あり
測定時期のみが、CDratio(C/D比)に有意な影響を与えている。
FCZの投与量や、FCZの投与量と測定時期の交互作用は有意ではなかった。
一応、線形混合モデルの解析はここまでとなります。
→交互作用とは?
試してみる。
アクティブデータセット > 変数の操作 > 計算式を入力して新たな変数を作成する
WeeksNum
WeeksNum2
ifelse(WeeksNum==3, 5, WeeksNum)
これで、WeeksNumの3が5になった新しい変数WeeksNum2 が作成される
次に、もう一度、線形混合モデルを実施する(今回は、1,2,5週で解析する。)
統計解析 > 連続変数の解析 > 線形混合モデル
今回は、
CDratio ~ FCZ * WeeksNum2 + ( WeeksNum2 | id)
(C/D比:血中CSA濃度) ~ (フルコナゾール投与量) * (移植後週数) + ( (移植後週数) | (患者個人))
結果としては、
Fixes effects: のところで、WeeksNumのみが、Pr=0.0375 で、有意差あり
測定時期のみが、CDratio(C/D比)に有意な影響を与えている。
FCZの投与量や、FCZの投与量と測定時期の交互作用は有意ではなかった。
なお、『線形混合モデル』は、正規分布に従うと想定される連続変数だけを「従属変数」(今回ではFCZ投与量と、移植後週数)として解析対象にできるが、
『一般化線型混合モデル』を使用すれば、二値変数など、様々なデータを解析対象とした混合モデル解析も可能になる。
EZRのメニューには、『一般化線型混合モデル』は含まれていないが、
Rコマンダーの標準メニューには、『一般化線型混合モデル』が含まれている。
【Rコマンダー】標準メニュー > 統計量 > モデルへの適合 > 一般化線型混合モデル
Tips
EZRではアルファベット順に変数が並ぶので、
アクティブデータセットの操作 > 変数の操作 > 変数名を変更する
で、うまくアルファベット順に並ぶように、変数名を変更する。
変更後のデータは、EZRでは、rdaファイル or CSVファイルで出力可能。
CSVファイルで出力したい場合
アクティブデータセット > アクティブデータセットの更新・保存 > アクティブデータセットをエクスポートする(txt形式)
変数名をつける を on
文字列変数をクオーツで囲む は off
フィールドの区切り記号 は カンマ
保存するときの拡張子を、 txt ではなく、 csv にして保存。
すると、そのままダブルクリックでエクセルが起動して、うまく開くことができる。
欠損値のあるデータの読み込み
NA としておけば、csvファイルで読み込むときに、NAは欠損値として読み込んでくれる
!is.NA=true ???
参考サイト
21.Rで線形混合モデル
p値について:https://www.biometrics.gr.jp/news/all/ASA.pdf
https://elsur.jpn.org/mt/2020/02/002839.html
読了:Bates, et al. (2015?) lme4::lmer()でたのしい線形混合モデリングrebuilt: 2020年11月16日 22:53
→ Rで線形混合モデルを用いる場合は、lme4パッケージのlmer()関数を
lmer(Reaction ~ Days + (Days | Subject), data = sleepstudy)のように用いるとよいとのこと。
https://qiita.com/Hiroyuki1993/items/bc303e8200aab6f759f6
@Hiroyuki1993vが2018年06月23日に更新
Rのlmer関数がp値を出力しない理由